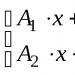Mengirimkan karya bagus Anda ke basis pengetahuan itu mudah. Gunakan formulir di bawah ini
Pelajar, mahasiswa pascasarjana, ilmuwan muda yang menggunakan basis pengetahuan dalam studi dan pekerjaan mereka akan sangat berterima kasih kepada Anda.
Diposting pada http://www.allbest.ru/
Kementerian Pendidikan dan Ilmu Pengetahuan Federasi Rusia
Universitas Ekonomi dan Manajemen Negeri Novosibirsk "NINKh"
Fakultas Teknologi Informasi
Departemen Teknologi Informasi Terapan
dalam disiplin Logika fuzzy dan jaringan saraf
Pengenalan pola
Arah: Informatika bisnis (bisnis elektronik)
Nama lengkap siswa: Mazur Ekaterina Vitalievna
Diperiksa oleh: Pavlova Anna Illarionovna
Novosibirsk 2016
- Perkenalan
- 1. Konsep pengakuan
- 1.1 Sejarah perkembangan
- 1.2 Klasifikasi metode pengenalan pola
- 2. Metode pengenalan pola
- 3. Ciri-ciri umum masalah pengenalan pola dan jenisnya
- 4. Permasalahan dan prospek pengembangan pengenalan pola
- 4.1 Penerapan pengenalan pola dalam praktik
- Kesimpulan
Perkenalan
Untuk waktu yang cukup lama, masalah pengenalan pola hanya dilihat dari sudut pandang biologis. Dalam hal ini, hanya karakteristik kualitatif yang diamati, yang tidak memungkinkan untuk menggambarkan mekanisme yang berfungsi.
Konsep tersebut diperkenalkan oleh N. Wiener pada awal abad ke-20 sibernetika(ilmu tentang hukum umum proses kendali dan transmisi informasi pada mesin, organisme hidup, dan masyarakat), memungkinkan untuk memperkenalkan metode kuantitatif dalam hal pengenalan. Artinya, untuk merepresentasikan proses ini (pada dasarnya fenomena alam) dengan menggunakan metode matematika.
Teori pengenalan pola merupakan salah satu cabang utama sibernetika, baik secara teoritis maupun terapan. Dengan demikian, otomatisasi beberapa proses melibatkan penciptaan perangkat yang mampu merespons perubahan karakteristik lingkungan eksternal dengan sejumlah reaksi positif.
Dasar pemecahan masalah tingkat ini adalah hasil teori klasik solusi statistik. Dalam kerangka kerjanya, algoritma dibangun untuk menentukan kelas di mana objek yang dikenali dapat diklasifikasikan.
Tujuan dari karya ini adalah untuk mengenal konsep-konsep teori pengenalan pola: untuk mengungkap definisi utama, mempelajari sejarah kemunculannya, dan menyoroti metode dan prinsip utama teori tersebut.
Relevansi topik ini terletak pada kenyataan bahwa saat ini pengenalan pola merupakan salah satu bidang utama sibernetika. Oleh karena itu, dalam beberapa tahun terakhir ini semakin banyak digunakan: menyederhanakan interaksi manusia dengan komputer dan menciptakan prasyarat untuk penggunaan berbagai sistem kecerdasan buatan.
aplikasi pengenalan gambar
1. Konsep pengakuan
Untuk waktu yang lama, masalah pengenalan hanya menarik perhatian para ilmuwan di bidang matematika terapan. Alhasil, karya-karya R. Fischer tercipta di 20an, mengarah pada pembentukan analisis diskriminan - salah satu cabang teori dan praktik pengenalan pola. DI DALAM 40an A. N. Kolmogorov dan A. Ya. Khinchin menetapkan tujuan untuk memisahkan campuran dari dua distribusi. Dan masuk 50-60an tahun abad kedua puluh, berdasarkan sejumlah besar karya, teori keputusan statistik muncul. Dalam kerangka sibernetika, arah baru mulai muncul terkait dengan pengembangan landasan teoritis dan implementasi praktis mekanisme, serta sistem yang dirancang untuk mengenali objek dan proses. Disiplin baru ini disebut "Pengenalan Pola".
Pengenalan pola(objek) adalah tugas mengidentifikasi suatu objek berdasarkan gambarnya (pengenalan optik), rekaman audio (pengenalan akustik) atau karakteristik lainnya. Gambar adalah pengelompokan klasifikasi yang memungkinkan Anda menggabungkan sekelompok objek menurut kriteria tertentu. Gambar memiliki ciri khas, yang dimanifestasikan dalam kenyataan bahwa pengenalan dengan sejumlah fenomena yang terbatas dari satu himpunan memungkinkan untuk mengenali sejumlah besar perwakilannya. Dalam rumusan klasik masalah pengenalan, himpunan dibagi menjadi beberapa bagian.
Salah satu definisi dasar juga merupakan konsep banyak sekali. Dalam komputer, himpunan adalah himpunan elemen tak berulang yang berjenis sama. “Tidak berulang” berarti bahwa suatu elemen dalam suatu himpunan ada atau tidak. Himpunan universal berisi semua elemen yang mungkin; himpunan kosong tidak berisi semua elemen yang mungkin.
Teknik menugaskan suatu elemen pada suatu gambar disebut aturan yang menentukan. Konsep penting lainnya adalah metrik- menentukan jarak antar elemen himpunan. Semakin kecil jarak ini, semakin mirip objek (simbol, suara, dll) yang kita kenali. Secara standar, elemen ditentukan sebagai sekumpulan angka, dan metrik ditentukan sebagai beberapa jenis fungsi. Efisiensi program bergantung pada pilihan representasi gambar dan implementasi metrik: algoritma pengenalan yang sama dengan metrik berbeda akan membuat kesalahan dengan frekuensi berbeda.
Pelatihan biasanya disebut proses berkembangnya suatu sistem tertentu reaksi tertentu terhadap faktor-faktor sinyal eksternal yang serupa melalui dampaknya yang berulang-ulang pada sistem. Belajar mandiri berbeda dengan pelatihan karena di sini informasi tambahan tentang reaksi tidak diberikan ke sistem.
Contoh tugas pengenalan pola adalah:
Pengenalan surat;
Pengenalan kode batang;
Pengenalan plat nomor;
Pengenalan wajah dan data biometrik lainnya;
Pengenalan ucapan, dll.
1.1 Cerita perkembangan
Pada pertengahan tahun 50-an, R. Penrose mempertanyakan model jaringan saraf otak, dengan menunjukkan peran penting efek mekanika kuantum dalam fungsinya. Berdasarkan hal tersebut, F. Rosenblatt mengembangkan model pembelajaran pengenalan gambar visual yang disebut perceptron.
Menggambar1 - Sirkuit Perceptron
Selanjutnya, berbagai generalisasi perceptron ditemukan, dan fungsi neuron menjadi rumit: neuron tidak hanya dapat mengalikan bilangan masukan dan membandingkan hasilnya dengan nilai ambang batas, tetapi juga menerapkan fungsi yang lebih kompleks pada bilangan tersebut. Gambar 2 menunjukkan salah satu komplikasi tersebut:
Beras. 2 Diagram jaringan saraf.
Selain itu, topologi jaringan saraf bisa menjadi lebih rumit. Misalnya seperti ini:
Gambar 3 - Diagram jaringan saraf Rosenblatt.
Jaringan saraf, sebagai objek kompleks untuk analisis matematis, bila digunakan dengan benar, memungkinkan ditemukannya hukum data yang sangat sederhana. Namun keunggulan ini juga merupakan sumber potensi kesalahan. Kesulitan analisis, dalam kasus umum, hanya dijelaskan oleh struktur yang kompleks, tetapi, sebagai konsekuensinya, oleh kemungkinan yang hampir tidak ada habisnya untuk menggeneralisasi berbagai macam pola.
1.2 Klasifikasimetodepengakuangambar
Seperti yang telah kita catat, pengenalan pola mengacu pada tugas membangun hubungan kesetaraan antara model gambar tertentu dari objek di dunia nyata atau dunia ideal.
Hubungan ini menentukan kepemilikan objek yang dikenali ke dalam kelas apa pun, yang dianggap sebagai unit independen.
Saat membangun algoritma pengenalan, kelas-kelas ini dapat ditentukan oleh peneliti yang menggunakan idenya sendiri atau menggunakan informasi tambahan tentang persamaan atau perbedaan objek dalam konteks tugas yang diberikan. Dalam hal ini kita berbicara tentang “pengakuan dengan seorang guru.” Di tempat lain, mis. Ketika sistem otomatis memecahkan masalah klasifikasi tanpa melibatkan informasi tambahan, sistem tersebut disebut “pengenalan tanpa pengawasan”.
Dalam karya V.A. Duke memberikan gambaran akademis tentang metode pengenalan dan menggunakan dua cara utama untuk merepresentasikan pengetahuan:
Intensional (berupa diagram hubungan antar atribut);
Ekstensional menggunakan fakta tertentu (objek, contoh).
Representasi yang disengaja menangkap pola yang menjelaskan struktur data. Sehubungan dengan masalah diagnostik, fiksasi tersebut terdiri dari penentuan operasi pada karakteristik objek yang mengarah pada hasil yang diinginkan. Representasi yang disengaja diimplementasikan melalui operasi pada nilai dan tidak melibatkan operasi pada objek tertentu.
Pada gilirannya, representasi pengetahuan ekstensional dikaitkan dengan deskripsi dan fiksasi objek tertentu dari area subjek dan diimplementasikan dalam operasi, yang elemen-elemennya merupakan objek sebagai sistem independen.
Dengan demikian, dasar klasifikasi metode pengenalan yang dikemukakan oleh V.A. Duke, ditetapkan hukum-hukum dasar yang mendasari cara kognisi manusia pada prinsipnya. Hal ini menempatkan pembagian kelas-kelas ini pada posisi khusus dibandingkan dengan klasifikasi lain yang kurang dikenal, yang dengan latar belakang ini terlihat dibuat-buat dan tidak lengkap.
2. Metodepengenalan pola
Metode kekerasan. Dalam metode ini, perbandingan dilakukan dengan database tertentu, di mana untuk setiap objek disajikan pilihan berbeda untuk memodifikasi tampilan. Misalnya, untuk pengenalan pola optik, Anda dapat menggunakan metode penghitungan pada sudut atau skala yang berbeda, perpindahan, deformasi, dll. Untuk huruf, Anda dapat menghitung font atau propertinya. Dalam hal pengenalan pola bunyi, dilakukan perbandingan dengan beberapa pola yang diketahui (sebuah kata yang diucapkan oleh banyak orang). Selanjutnya dilakukan analisis lebih mendalam terhadap ciri-ciri citra. Dalam kasus pengenalan optik, ini mungkin merupakan penentuan karakteristik geometris. Dalam hal ini, sampel suara dilakukan analisis frekuensi dan amplitudo.
Metode selanjutnya - penggunaan jaringan syaraf tiruan(IN). Hal ini memerlukan sejumlah besar contoh tugas pengenalan, atau struktur jaringan saraf khusus yang mempertimbangkan secara spesifik tugas yang diberikan. Namun, metode ini sangat efisien dan produktif.
Metode berdasarkan estimasi kepadatan distribusi nilai fitur. Dipinjam dari teori klasik keputusan statistik, di mana objek kajian dianggap sebagai realisasi variabel acak multidimensi yang didistribusikan dalam ruang fitur menurut hukum tertentu. Mereka didasarkan pada skema pengambilan keputusan Bayesian yang mengacu pada probabilitas awal objek yang termasuk dalam kelas tertentu dan kepadatan distribusi fitur bersyarat.
Sekelompok metode yang didasarkan pada estimasi kepadatan distribusi nilai fitur berhubungan langsung dengan metode analisis diskriminan. Pendekatan Bayesian dalam pengambilan keputusan adalah salah satu metode parametrik yang paling berkembang dalam statistik modern, yang mana ekspresi analitis dari hukum distribusi (hukum normal) diasumsikan diketahui dan hanya sejumlah kecil parameter (vektor mean dan matriks kovarians). ) perlu diestimasi. Kesulitan utama dalam menggunakan metode ini adalah kebutuhan untuk mengingat seluruh sampel pelatihan untuk menghitung perkiraan kepadatan dan sensitivitas yang tinggi terhadap sampel pelatihan.
Metode berdasarkan asumsi tentang kelas fungsi keputusan. Dalam kelompok ini, jenis fungsi keputusan dianggap diketahui dan fungsi kualitasnya ditentukan. Berdasarkan fungsi ini, perkiraan optimal terhadap fungsi keputusan ditemukan dengan menggunakan urutan pelatihan. Fungsi kualitas aturan keputusan biasanya dikaitkan dengan kesalahan. Keuntungan utama dari metode ini adalah kejelasan rumusan matematis dari masalah pengenalan. Kemampuan untuk mengekstrak pengetahuan baru tentang sifat suatu objek, khususnya pengetahuan tentang mekanisme interaksi atribut, di sini pada dasarnya dibatasi oleh struktur yang diberikan. interaksi, ditetapkan dalam bentuk fungsi keputusan yang dipilih.
Metode perbandingan dengan prototipe. Ini adalah metode pengenalan ekstensional yang paling mudah dalam praktiknya. Digunakan ketika kelas yang dikenali ditampilkan sebagai kelas geometri kompak. Kemudian pusat pengelompokan geometri (atau objek yang paling dekat dengan pusat) dipilih sebagai titik prototipe.
Untuk mengklasifikasikan objek yang tidak terdefinisi, prototipe terdekat ditemukan dan objek tersebut termasuk dalam kelas yang sama dengannya. Jelasnya, tidak ada gambaran umum yang terbentuk dalam metode ini. Berbagai jenis jarak dapat digunakan sebagai ukuran.
k metode tetangga terdekat. Metode ini terdiri dari fakta bahwa ketika mengklasifikasikan objek yang tidak diketahui, ditemukan sejumlah (k) fitur terdekat secara geometris dalam ruang tetangga terdekat lainnya yang sudah diketahui keanggotaannya dalam kelas mana pun. Keputusan untuk mengklasifikasikan objek yang tidak diketahui dibuat dengan menganalisis informasi tentang tetangga terdekatnya. Kebutuhan untuk mengurangi jumlah objek dalam sampel pelatihan (preseden diagnostik) merupakan kelemahan metode ini, karena hal ini mengurangi keterwakilan sampel pelatihan.
Berdasarkan fakta bahwa algoritme pengenalan yang berbeda berperilaku berbeda pada sampel yang sama, muncul pertanyaan tentang aturan keputusan sintetik yang akan menggunakan kekuatan semua algoritme. Untuk tujuan ini, terdapat metode sintetik atau kelompok aturan pengambilan keputusan yang menggabungkan aspek paling positif dari setiap metode.
Untuk menyimpulkan tinjauan metode pengenalan, kami akan menyajikan intisari di atas dalam tabel ringkasan, menambahkan juga beberapa metode lain yang digunakan dalam praktik.
Tabel 1. Tabel klasifikasi metode pengenalan, perbandingan bidang penerapan dan keterbatasannya
|
Klasifikasi metode pengenalan |
Lingkup aplikasi |
Keterbatasan (kekurangan) |
||
|
Metode pengenalan intensif |
Metode berdasarkan perkiraan kepadatan |
Masalah dengan distribusi yang diketahui (normal), kebutuhan untuk mengumpulkan statistik yang besar |
Kebutuhan untuk menghitung seluruh sampel pelatihan selama pengenalan, sensitivitas tinggi terhadap non-representatif sampel pelatihan dan artefak |
|
|
Metode Berbasis Asumsi |
Kelas harus dapat dipisahkan dengan baik |
Jenis fungsi keputusan harus diketahui terlebih dahulu. Ketidakmampuan untuk memperhitungkan pengetahuan baru tentang korelasi antar sifat |
||
|
Metode Boolean |
Masalah kecil |
Ketika memilih aturan keputusan yang logis, pencarian yang mendalam diperlukan. Intensitas tenaga kerja yang tinggi |
||
|
Metode linguistik |
Tugas menentukan tata bahasa dari sekumpulan pernyataan (deskripsi objek) tertentu sulit untuk diformalkan. Masalah teoritis yang belum terpecahkan |
|||
|
Metode pengenalan ekstensional |
Metode perbandingan dengan prototipe |
Masalah dimensi ruang fitur yang kecil |
Ketergantungan hasil klasifikasi yang tinggi pada metrik. Metrik optimal tidak diketahui |
|
|
k metode tetangga terdekat |
Ketergantungan hasil klasifikasi yang tinggi pada metrik. Perlunya pencacahan lengkap sampel pelatihan selama pengenalan. Upaya komputasi |
|||
|
Algoritma untuk menghitung estimasi (ABO) |
Masalah berdimensi kecil dari segi jumlah kelas dan fitur |
Ketergantungan hasil klasifikasi pada metrik. Perlunya pencacahan lengkap sampel pelatihan selama pengenalan. Kompleksitas teknis yang tinggi dari metode ini |
||
|
Decision Rule Collectives (DRCs) adalah metode sintetik. |
Masalah berdimensi kecil dari segi jumlah kelas dan fitur |
Kompleksitas teknis metode yang sangat tinggi, banyaknya permasalahan teoritis yang belum terpecahkan, baik dalam menentukan bidang kompetensi metode privat maupun dalam metode privat itu sendiri |
3. Ciri-ciri umum masalah pengenalan pola dan jenisnya
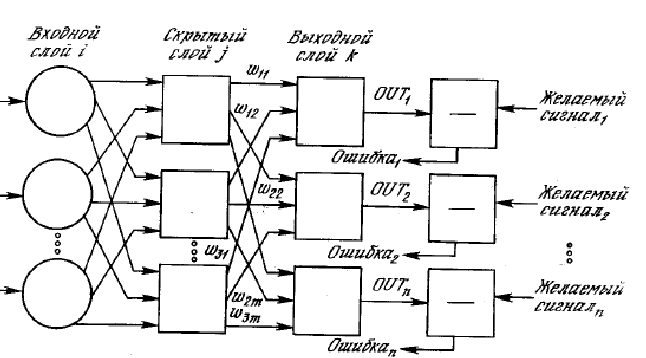
Struktur umum sistem pengenalan dan tahapannya ditunjukkan pada Gambar 4:
Gambar 4 - Struktur sistem pengenalan
Tugas pengenalan memiliki tahapan karakteristik sebagai berikut:
Mengubah data awal menjadi bentuk pengenalan yang mudah;
Recognition (menunjukkan bahwa suatu objek termasuk dalam kelas tertentu).
Dalam soal ini, Anda dapat memperkenalkan konsep kesamaan objek dan merumuskan seperangkat aturan yang menjadi dasar dimasukkannya suatu objek ke dalam satu atau kelas yang berbeda.
Anda juga dapat mengoperasikan dengan serangkaian contoh, klasifikasi yang diketahui dan yang, dalam bentuk deskripsi yang diberikan, dapat dinyatakan ke dalam algoritma pengenalan untuk penyesuaian tugas selama proses pembelajaran.
Kesulitan dalam memecahkan masalah pengenalan dikaitkan dengan ketidakmampuan untuk menerapkan metode matematika klasik tanpa koreksi (seringkali informasi untuk model matematika yang akurat tidak tersedia)
Jenis tugas pengenalan berikut ini dibedakan:
Tugas pengenalan adalah menugaskan objek yang disajikan sesuai dengan deskripsinya ke salah satu kelas yang diberikan (supervised learning);
Tugas klasifikasi otomatis adalah mempartisi suatu himpunan ke dalam sistem kelas-kelas yang terpisah (taksonomi, analisis klaster, pembelajaran mandiri);
Tugas memilih sekumpulan atribut informatif selama pengenalan;
Tugas membawa data awal ke dalam bentuk yang nyaman;
Pengenalan dan klasifikasi dinamis;
Masalah peramalan - yaitu, keputusan harus berhubungan dengan titik tertentu di masa depan.
Ada dua masalah tersulit dalam sistem pengenalan yang ada:
Masalah “1001 kelas” - menambahkan 1 kelas ke 1000 kelas yang sudah ada menyebabkan kesulitan dalam melatih ulang sistem dan memeriksa data yang diterima sebelumnya;
Masalah “korelasi antara kamus dan sumber” paling menonjol dalam pengenalan ucapan. Sistem yang ada saat ini dapat mengenali sejumlah besar kata dari sekelompok kecil individu atau sejumlah kecil kata dari sekelompok besar individu. Sulit juga mengenali banyak wajah dengan riasan atau seringai.
Jaringan saraf tidak menyelesaikan masalah ini secara langsung, namun karena sifatnya, jaringan saraf lebih mudah beradaptasi terhadap perubahan urutan masukan.
4. Masalah dan prospekperkembanganpengenalan pola
4.1 Penerapan pengenalan pola dalam praktik
Secara umum masalah pengenalan pola terdiri dari dua bagian yaitu pelatihan dan pengenalan. Pembelajaran dilakukan dengan menunjukkan benda-benda mandiri dan menugaskannya ke kelas tertentu. Sebagai hasil dari pelatihan, sistem pengenalan harus memperoleh kemampuan untuk merespons dengan reaksi yang sama terhadap semua objek dalam satu gambar dan berbeda terhadap semua objek lainnya. Penting bahwa selama proses pembelajaran hanya objek itu sendiri dan afiliasinya dengan gambar yang ditunjukkan. Pelatihan diikuti dengan proses pengenalan yang mencirikan tindakan sistem yang sudah dilatih. Otomatisasi prosedur-prosedur ini adalah masalahnya.
Sebelum Anda mulai menganalisis suatu objek, Anda perlu memperoleh informasi yang pasti, teratur, dan akurat tentang objek tersebut. Informasi tersebut adalah sekumpulan properti objek, tampilannya pada berbagai organ perseptif dari sistem pengenalan.
Namun setiap objek pengamatan dapat memberikan pengaruh yang berbeda-beda, tergantung kondisi persepsinya. Selain itu, objek dalam gambar yang sama bisa sangat berbeda satu sama lain.
Setiap pemetaan suatu objek ke organ perseptif sistem pengenalan, terlepas dari posisinya relatif terhadap organ-organ ini, biasanya disebut gambar objek, dan kumpulan gambar tersebut, yang disatukan oleh beberapa sifat umum, disebut gambar. Jika deskripsi awal (ruang fitur) berhasil dipilih, tugas pengenalan mungkin menjadi cukup mudah, dan sebaliknya, pilihan yang gagal dapat menyebabkan pemrosesan informasi lebih lanjut yang sangat rumit, atau tidak adanya solusi sama sekali.
Pengenalan objek, sinyal, situasi, fenomena adalah tugas paling umum yang perlu diselesaikan seseorang setiap detik. Untuk ini, sumber daya otak yang sangat besar digunakan, yang diperkirakan dengan indikator seperti jumlah neuron 10 10.
Selain itu, pengakuan juga selalu ditemui dalam teknologi. Perhitungan dalam jaringan neuron formal dalam banyak hal mirip dengan pemrosesan informasi di otak. Dalam dekade terakhir, neurocomputing telah mendapatkan popularitas ekstrim dan telah menjadi disiplin ilmu teknik yang terkait dengan produksi produk komersial. Sejumlah besar pekerjaan sedang dilakukan untuk menciptakan basis elemen untuk neurocomputing.
Ciri khas utama mereka adalah kemampuan untuk memecahkan masalah-masalah yang tidak diformalkan, yang karena satu dan lain hal, tidak ada algoritma solusi yang diusulkan. Neurokomputer menawarkan teknologi yang relatif sederhana untuk menurunkan algoritma melalui pembelajaran. Inilah keunggulan utama mereka. Oleh karena itu, neurocomputing ternyata relevan saat ini – pada masa kejayaan multimedia, ketika perkembangan global memerlukan perkembangan teknologi baru yang berkaitan erat dengan pengenalan gambar.
Salah satu masalah utama dalam pengembangan dan penerapan kecerdasan buatan adalah masalah pengenalan gambar audio dan visual. Semua teknologi lainnya sudah siap diterapkan dalam bidang kedokteran, biologi, dan sistem keamanan. Dalam dunia kedokteran, pengenalan pola membantu dokter membuat diagnosis yang lebih akurat; di pabrik, pengenalan pola digunakan untuk memprediksi cacat pada sejumlah barang. Sistem identifikasi pribadi biometrik juga didasarkan pada hasil pengenalan sebagai inti algoritmiknya. Perkembangan lebih lanjut dan desain komputer yang mampu melakukan komunikasi lebih langsung dengan manusia dalam bahasa alami manusia dan melalui ucapan tidak dapat diselesaikan tanpa pengenalan. Di sinilah timbul pertanyaan tentang pengembangan robotika dan sistem kendali buatan yang memuat sistem pengenalan sebagai subsistem vital.
Kesimpulan
Sebagai hasil dari pekerjaan tersebut, gambaran singkat tentang definisi utama konsep cabang sibernetika seperti pengenalan pola dibuat, metode pengenalan disorot, dan tugas dirumuskan.
Tentu saja banyak arah perkembangan ilmu ini. Selain itu, sebagaimana dinyatakan dalam salah satu bab, pengakuan merupakan salah satu bidang utama pembangunan saat ini. Dengan demikian, perangkat lunak dalam beberapa dekade mendatang dapat menjadi lebih menarik bagi pengguna dan kompetitif di pasar modern jika perangkat lunak tersebut memperoleh format komersial dan mulai didistribusikan ke sejumlah besar konsumen.
Penelitian lebih lanjut dapat ditujukan pada aspek-aspek berikut: analisis mendalam tentang metode pemrosesan utama dan pengembangan metode pengenalan baru yang digabungkan atau dimodifikasi. Berdasarkan penelitian yang dilakukan, dimungkinkan untuk mengembangkan sistem pengenalan fungsional, yang dengannya dimungkinkan untuk menguji efektivitas metode pengenalan yang dipilih.
Referensi
1. David Formais, Jean Pons Visi komputer. Pendekatan modern, 2004
2. Aizerman M.A., Braverman E.M., Rozonoer L.I. Metode fungsi potensial dalam teori pembelajaran mesin. - M.: Nauka, 2004.
3. Zhuravlev Yu.I. Tentang pendekatan aljabar untuk memecahkan masalah pengenalan atau klasifikasi // Masalah Sibernetika. M.: Nauka, 2005. - Edisi. 33.
4. Mazurov V.D. Komite sistem ketidaksetaraan dan masalah pengakuan // Sibernetika, 2004, No.2.
5. Potapov A.S. Pengenalan pola dan persepsi mesin. - SPb: Politekhnika, 2007.
6. Minsky M., Papert S. Perceptron. - M.: Mir, 2007.
7. Rastrigin L. A., Erenshtein R. Kh. Metode pengakuan kolektif. M.Energoizdat, 2006.
8. Rudakov K.V. Tentang teori aljabar pembatasan universal dan lokal untuk masalah klasifikasi // Pengakuan, klasifikasi, perkiraan. Metode matematika dan penerapannya. Jil. 1. - M.: Nauka, 2007.
9. Fu K. Metode struktural dalam pengenalan pola. - M.: Mir, 2005.
Diposting di Allbest.ru
...Dokumen serupa
Konsep dasar teori pengenalan pola dan signifikansinya. Inti dari teori matematika pengenalan pola. Tugas utama yang muncul ketika mengembangkan sistem pengenalan gambar. Klasifikasi sistem pengenalan pola waktu nyata.
tugas kursus, ditambahkan 15/01/2014
Konsep dan fitur membangun algoritma pengenalan pola. Berbagai pendekatan terhadap tipologi metode pengenalan. Mempelajari cara-cara dasar merepresentasikan pengetahuan. Karakteristik metode intensional dan ekstensional, penilaian kualitasnya.
presentasi, ditambahkan 01/06/2014
Landasan teoritis pengenalan pola. Diagram fungsional sistem pengenalan. Penerapan metode Bayesian dalam memecahkan masalah pengenalan pola. Segmentasi citra Bayesian. Model TAN untuk memecahkan masalah klasifikasi citra.
tesis, ditambahkan 13/10/2017
Tinjauan permasalahan yang timbul dalam pengembangan sistem pengenalan pola. Pengklasifikasi gambar yang dapat dilatih. Algoritma Perceptron dan modifikasinya. Pembuatan program yang dirancang untuk mengklasifikasikan gambar menggunakan metode kesalahan kuadrat terkecil.
tugas kursus, ditambahkan 04/05/2015
Metode pengenalan pola (pengklasifikasi): Bayesian, linier, metode fungsi potensial. Pengembangan program untuk mengenali seseorang dari fotonya. Contoh cara kerja pengklasifikasi, hasil eksperimen keakuratan metode.
tugas kursus, ditambahkan 15/08/2011
Pembuatan perangkat lunak yang melakukan pengenalan gambar visual berdasarkan jaringan saraf tiruan. Metode yang digunakan untuk pengenalan pola. Kekacauan Selfridge. Rosenblatt Perceptron. Aturan pembentukan kode rantai.
tesis, ditambahkan 04/06/2014
Pengenalan pola adalah tugas mengidentifikasi suatu objek atau menentukan propertinya dari gambar atau rekaman audio. Sejarah perubahan teoritis dan teknis di bidang ini. Metode dan prinsip yang digunakan dalam teknologi komputer untuk pengenalan.
abstrak, ditambahkan 04/10/2010
Konsep sistem pengenalan pola. Klasifikasi sistem pengenalan. Pengembangan sistem pengenalan bentuk benda mikro. Algoritme untuk membuat sistem pengenalan objek mikro pada kristalogram, fitur implementasinya dalam lingkungan perangkat lunak.
tugas kursus, ditambahkan 21/06/2014
Memilih jenis dan struktur jaringan saraf. Pemilihan metode pengenalan, diagram blok jaringan Hopfield. Melatih sistem pengenalan pola. Fitur bekerja dengan program ini, kelebihan dan kekurangannya. Deskripsi antarmuka pengguna dan bentuk layar.
tugas kursus, ditambahkan 14/11/2013
Munculnya sistem pengenalan otomatis teknis. Manusia sebagai elemen atau penghubung sistem otomatis yang kompleks. Kemungkinan perangkat pengenalan otomatis. Tahapan pembuatan sistem pengenalan pola. Proses pengukuran dan pengkodean.
Metode kekerasan. Dalam metode ini, perbandingan dilakukan dengan database tertentu, di mana untuk setiap objek disajikan pilihan berbeda untuk memodifikasi tampilan. Misalnya, untuk pengenalan pola optik, Anda dapat menggunakan metode penghitungan pada sudut atau skala yang berbeda, perpindahan, deformasi, dll. Untuk huruf, Anda dapat menghitung font atau propertinya. Dalam hal pengenalan pola bunyi, dilakukan perbandingan dengan beberapa pola yang diketahui (sebuah kata yang diucapkan oleh banyak orang). Selanjutnya dilakukan analisis lebih mendalam terhadap ciri-ciri citra. Dalam kasus pengenalan optik, ini mungkin merupakan penentuan karakteristik geometris. Dalam hal ini, sampel suara dilakukan analisis frekuensi dan amplitudo.
Metode selanjutnya - penggunaan jaringan syaraf tiruan(IN). Hal ini memerlukan sejumlah besar contoh tugas pengenalan, atau struktur jaringan saraf khusus yang mempertimbangkan secara spesifik tugas yang diberikan. Namun, metode ini sangat efisien dan produktif.
Metode berdasarkan estimasi kepadatan distribusi nilai fitur. Dipinjam dari teori klasik keputusan statistik, di mana objek kajian dianggap sebagai realisasi variabel acak multidimensi yang didistribusikan dalam ruang fitur menurut hukum tertentu. Mereka didasarkan pada skema pengambilan keputusan Bayesian yang mengacu pada probabilitas awal objek yang termasuk dalam kelas tertentu dan kepadatan distribusi fitur bersyarat.
Sekelompok metode yang didasarkan pada estimasi kepadatan distribusi nilai fitur berhubungan langsung dengan metode analisis diskriminan. Pendekatan Bayesian dalam pengambilan keputusan adalah salah satu metode parametrik yang paling berkembang dalam statistik modern, yang mana ekspresi analitis dari hukum distribusi (hukum normal) diasumsikan diketahui dan hanya sejumlah kecil parameter (vektor mean dan matriks kovarians). ) perlu diestimasi. Kesulitan utama dalam menggunakan metode ini adalah kebutuhan untuk mengingat seluruh sampel pelatihan untuk menghitung perkiraan kepadatan dan sensitivitas yang tinggi terhadap sampel pelatihan.
Metode berdasarkan asumsi tentang kelas fungsi keputusan. Dalam kelompok ini, jenis fungsi keputusan dianggap diketahui dan fungsi kualitasnya ditentukan. Berdasarkan fungsi ini, perkiraan optimal terhadap fungsi keputusan ditemukan dengan menggunakan urutan pelatihan. Fungsi kualitas aturan keputusan biasanya dikaitkan dengan kesalahan. Keuntungan utama metode ini adalah kejelasan rumusan matematis dari masalah pengenalan. Kemungkinan mengekstraksi pengetahuan baru tentang sifat suatu objek, khususnya pengetahuan tentang mekanisme interaksi atribut, di sini pada dasarnya dibatasi oleh struktur interaksi tertentu, yang ditetapkan dalam bentuk fungsi keputusan yang dipilih.
Metode perbandingan dengan prototipe. Ini adalah metode pengenalan ekstensional yang paling mudah dalam praktiknya. Digunakan ketika kelas yang dikenali ditampilkan sebagai kelas geometri kompak. Kemudian pusat pengelompokan geometri (atau objek yang paling dekat dengan pusat) dipilih sebagai titik prototipe.
Untuk mengklasifikasikan objek yang tidak terdefinisi, prototipe terdekat ditemukan dan objek tersebut termasuk dalam kelas yang sama dengannya. Jelasnya, tidak ada gambaran umum yang terbentuk dalam metode ini. Berbagai jenis jarak dapat digunakan sebagai ukuran.
Metode k-tetangga terdekat. Metode ini terdiri dari fakta bahwa ketika mengklasifikasikan objek yang tidak diketahui, ditemukan sejumlah (k) fitur terdekat secara geometris dalam ruang tetangga terdekat lainnya yang sudah diketahui keanggotaannya dalam kelas mana pun. Keputusan untuk mengklasifikasikan objek yang tidak diketahui dibuat dengan menganalisis informasi tentang tetangga terdekatnya. Kebutuhan untuk mengurangi jumlah objek dalam sampel pelatihan (preseden diagnostik) merupakan kelemahan metode ini, karena hal ini mengurangi keterwakilan sampel pelatihan.
Berdasarkan fakta bahwa algoritme pengenalan yang berbeda berperilaku berbeda pada sampel yang sama, muncul pertanyaan tentang aturan keputusan sintetik yang akan menggunakan kekuatan semua algoritme. Untuk tujuan ini, terdapat metode sintetik atau kelompok aturan pengambilan keputusan yang menggabungkan aspek paling positif dari setiap metode.
Untuk menyimpulkan tinjauan metode pengenalan, kami akan menyajikan intisari di atas dalam tabel ringkasan, menambahkan juga beberapa metode lain yang digunakan dalam praktik.
Tabel 1. Tabel klasifikasi metode pengenalan, perbandingan bidang penerapan dan keterbatasannya
|
Klasifikasi metode pengenalan |
Lingkup aplikasi |
Keterbatasan (kekurangan) |
|
|
Metode pengenalan intensif |
Metode berdasarkan perkiraan kepadatan |
Masalah dengan distribusi yang diketahui (normal), kebutuhan untuk mengumpulkan statistik yang besar |
Kebutuhan untuk menghitung seluruh sampel pelatihan selama pengenalan, sensitivitas tinggi terhadap non-representatif sampel pelatihan dan artefak |
|
Metode Berbasis Asumsi |
Kelas harus dapat dipisahkan dengan baik |
Jenis fungsi keputusan harus diketahui terlebih dahulu. Ketidakmampuan untuk memperhitungkan pengetahuan baru tentang korelasi antar sifat |
|
|
Metode Boolean |
Masalah kecil |
Ketika memilih aturan keputusan yang logis, pencarian yang mendalam diperlukan. Intensitas tenaga kerja yang tinggi |
|
|
Metode linguistik |
Tugas menentukan tata bahasa dari sekumpulan pernyataan (deskripsi objek) tertentu sulit untuk diformalkan. Masalah teoritis yang belum terpecahkan |
||
|
Metode pengenalan ekstensional |
Metode perbandingan dengan prototipe |
Masalah dimensi ruang fitur yang kecil |
Ketergantungan hasil klasifikasi yang tinggi pada metrik. Metrik optimal tidak diketahui |
|
k metode tetangga terdekat |
Ketergantungan hasil klasifikasi yang tinggi pada metrik. Perlunya pencacahan lengkap sampel pelatihan selama pengenalan. Upaya komputasi |
||
|
Algoritma untuk menghitung estimasi (ABO) |
Masalah berdimensi kecil dari segi jumlah kelas dan fitur |
Ketergantungan hasil klasifikasi pada metrik. Perlunya pencacahan lengkap sampel pelatihan selama pengenalan. Kompleksitas teknis yang tinggi dari metode ini |
|
|
Decision Rule Collectives (DRCs) adalah metode sintetik. |
Masalah berdimensi kecil dari segi jumlah kelas dan fitur |
Kompleksitas teknis metode yang sangat tinggi, banyaknya permasalahan teoritis yang belum terpecahkan, baik dalam menentukan bidang kompetensi metode privat maupun dalam metode privat itu sendiri |
Secara umum, ada tiga metode pengenalan pola yang dapat dibedakan: Metode brute force. Dalam hal ini dilakukan perbandingan dengan database, dimana untuk setiap jenis objek disajikan berbagai modifikasi tampilan. Misalnya, untuk pengenalan pola optik, Anda dapat menggunakan metode menghitung penampakan suatu objek pada berbagai sudut, skala, perpindahan, deformasi, dll. Untuk huruf, Anda perlu menghitung font, properti font, dll. pengenalan gambar suara, oleh karena itu, perbandingan dibuat dengan beberapa pola yang diketahui (misalnya, sebuah kata yang diucapkan oleh beberapa orang).
Pendekatan kedua melibatkan analisis yang lebih mendalam terhadap karakteristik gambar. Dalam kasus pengenalan optik, ini mungkin merupakan penentuan berbagai karakteristik geometris. Dalam hal ini, sampel suara dikenai analisis frekuensi, amplitudo, dll.
Metode selanjutnya adalah penggunaan jaringan syaraf tiruan (JST). Metode ini memerlukan sejumlah besar contoh tugas pengenalan selama pelatihan, atau struktur jaringan saraf khusus yang mempertimbangkan kekhususan tugas ini. Namun, ia menawarkan efisiensi dan produktivitas yang lebih tinggi.
4. Sejarah pengenalan pola
Mari kita pertimbangkan secara singkat formalisme matematika dari pengenalan pola. Suatu objek dalam pengenalan pola digambarkan oleh sekumpulan karakteristik dasar (fitur, properti). Ciri-ciri utama dapat bersifat berbeda: ciri-ciri tersebut dapat diambil dari himpunan terurut dari tipe garis nyata, atau dari himpunan diskrit (yang, bagaimanapun, juga dapat memiliki struktur). Pemahaman tentang suatu objek ini konsisten dengan kebutuhan akan penerapan praktis pengenalan pola dan dengan pemahaman kita tentang mekanisme persepsi manusia terhadap suatu objek. Memang benar, kami percaya bahwa ketika seseorang mengamati (mengukur) suatu objek, informasi tentang objek tersebut tiba melalui sejumlah sensor (saluran yang dianalisis) yang terbatas ke otak, dan setiap sensor dapat dikaitkan dengan karakteristik objek yang sesuai. Selain fitur-fitur yang sesuai dengan pengukuran kita terhadap suatu objek, ada juga fitur yang dipilih, atau sekelompok fitur, yang kita sebut fitur klasifikasi, dan mencari tahu nilainya untuk vektor X tertentu adalah tugas yang dilakukan oleh sistem pengenalan alami dan buatan.
Jelas bahwa untuk menetapkan nilai ciri-ciri tersebut, diperlukan informasi tentang bagaimana ciri-ciri yang diketahui berkaitan dengan ciri-ciri yang mengklasifikasikannya. Informasi tentang hubungan ini diberikan dalam bentuk preseden, yaitu sekumpulan deskripsi objek yang memiliki nilai karakteristik klasifikasi yang diketahui. Dan berdasarkan informasi preseden ini, perlu untuk membangun aturan keputusan yang akan menetapkan deskripsi sewenang-wenang suatu objek nilai-nilai fitur klasifikasinya.
Pemahaman tentang masalah pengenalan pola ini telah ditetapkan dalam sains sejak tahun 50-an abad yang lalu. Dan kemudian diketahui bahwa produksi seperti itu bukanlah hal baru sama sekali. Kami telah menemukan formulasi serupa dan sudah ada metode analisis data statistik yang telah terbukti cukup baik, yang secara aktif digunakan untuk banyak masalah praktis, seperti misalnya diagnostik teknis. Oleh karena itu, langkah pertama pengenalan pola terjadi di bawah pendekatan statistik, yang menentukan masalah utama.
Pendekatan statistik didasarkan pada gagasan bahwa ruang asal benda adalah ruang probabilistik, dan tanda (karakteristik) benda merupakan variabel acak yang ditentukan di dalamnya. Kemudian tugas data scientist adalah, berdasarkan pertimbangan tertentu, mengajukan hipotesis statistik tentang sebaran fitur, atau lebih tepatnya, tentang ketergantungan fitur pengklasifikasian pada fitur lainnya. Hipotesis statistik, pada umumnya, adalah sekumpulan fungsi distribusi fitur yang ditentukan secara parametrik. Hipotesis statistik yang khas dan klasik adalah hipotesis tentang normalitas distribusi ini (para ahli statistik telah mengemukakan banyak sekali jenis hipotesis semacam itu). Setelah merumuskan hipotesis, tinggal menguji hipotesis tersebut pada data preseden. Pengujian ini terdiri dari pemilihan distribusi tertentu dari kumpulan distribusi yang awalnya ditentukan (parameter hipotesis distribusi) dan menilai keandalan (interval kepercayaan) pilihan tersebut. Sebenarnya fungsi distribusi ini adalah jawaban dari permasalahan tersebut, hanya saja objeknya tidak lagi diklasifikasikan secara jelas, tetapi dengan probabilitas tertentu untuk menjadi bagian dari kelas. Para ahli statistik juga telah mengembangkan pembenaran asimtotik untuk metode tersebut. Pembenaran tersebut dibuat sesuai dengan skema berikut: fungsi tertentu untuk kualitas pilihan distribusi ditetapkan (interval kepercayaan) dan ditunjukkan bahwa dengan peningkatan jumlah preseden, pilihan kami dengan probabilitas cenderung 1 menjadi benar dalam pengertian fungsional ini (interval kepercayaan cenderung 0). Ke depan, kami akan mengatakan bahwa pandangan statistik dari masalah pengenalan ternyata sangat bermanfaat tidak hanya dalam hal algoritma yang dikembangkan (yang mencakup metode analisis klaster dan diskriminan, regresi nonparametrik, dll.), tetapi juga kemudian dipimpin oleh Vapnik untuk penciptaan teori pengakuan statistik yang mendalam.
Namun, ada argumen kuat yang dibuat bahwa masalah pengenalan pola tidak dapat direduksi menjadi statistik. Masalah seperti itu pada prinsipnya dapat dilihat dari sudut pandang statistik dan hasil penyelesaiannya dapat diinterpretasikan secara statistik. Untuk melakukan ini, kita hanya perlu berasumsi bahwa ruang objek permasalahan bersifat probabilistik. Namun dari sudut pandang instrumentalisme, kriteria keberhasilan interpretasi statistik suatu metode pengenalan tertentu hanya dapat berupa adanya justifikasi metode tersebut dalam bahasa statistika sebagai salah satu cabang matematika. Pembenaran di sini berarti pengembangan persyaratan dasar untuk tugas yang menjamin keberhasilan penerapan metode ini. Namun, saat ini, untuk sebagian besar metode pengakuan, termasuk metode yang muncul secara langsung dalam kerangka pendekatan statistik, pembenaran yang memuaskan belum ditemukan. Selain itu, algoritma statistik yang paling umum digunakan saat ini, seperti diskriminan linier Fisher, jendela Parzen, algoritma EM, metode tetangga terdekat, belum lagi jaringan kepercayaan Bayesian, memiliki sifat heuristik yang kuat dan mungkin memiliki interpretasi yang berbeda dengan statistik. Dan terakhir, untuk semua hal di atas, harus ditambahkan bahwa selain perilaku asimtotik dari metode pengenalan, yang merupakan masalah utama statistik, praktik pengenalan menimbulkan pertanyaan tentang kompleksitas komputasi dan struktural dari metode yang jauh melampaui batas-batasnya. ruang lingkup teori probabilitas saja.
Jadi, bertentangan dengan aspirasi para ahli statistik untuk mempertimbangkan pengenalan pola sebagai cabang statistik, ide-ide yang sangat berbeda dimasukkan dalam praktik dan ideologi pengenalan. Salah satunya disebabkan oleh penelitian di bidang pengenalan pola visual dan didasarkan pada analogi berikut.
Seperti yang telah disebutkan, dalam kehidupan sehari-hari orang terus-menerus memecahkan (seringkali secara tidak sadar) masalah dalam mengenali berbagai situasi, gambaran pendengaran dan visual. Kemampuan komputer seperti itu, paling-paling, adalah sesuatu yang akan terjadi di masa depan. Oleh karena itu, beberapa pionir pengenalan pola menyimpulkan bahwa penyelesaian masalah ini pada komputer, secara umum, harus meniru proses berpikir manusia. Upaya paling terkenal untuk mendekati masalah dari sudut ini adalah studi terkenal F. Rosenblatt tentang perceptron.
Pada pertengahan tahun 50-an, tampaknya ahli neurofisiologi telah memahami prinsip-prinsip fisik otak (dalam buku “The New Mind of the King,” fisikawan teoretis terkenal Inggris R. Penrose dengan menarik mempertanyakan model jaringan saraf otak, dengan membenarkan peran penting efek mekanika kuantum dalam fungsinya; meskipun model ini dipertanyakan sejak awal, Berdasarkan penemuan ini, F. Rosenblatt mengembangkan model untuk mempelajari pengenalan gambar visual, yang disebutnya perceptron Rosenblatt, yang mewakili. fungsi berikut (Gbr. 1):
Gambar 1. Rangkaian Perceptron
Pada masukannya, perceptron menerima vektor objek, yang dalam karya Rosenblatt merupakan vektor biner yang menunjukkan piksel layar mana yang dihitamkan oleh gambar dan mana yang tidak. Selanjutnya, masing-masing tanda diumpankan ke masukan neuron, yang tindakannya adalah perkalian sederhana dengan bobot neuron tertentu. Hasilnya diumpankan ke neuron terakhir, yang menjumlahkannya dan membandingkan jumlah totalnya dengan ambang batas tertentu. Tergantung pada hasil perbandingan, objek input X dikenali diperlukan atau tidak. Kemudian tugas pengajaran pengenalan pola adalah memilih bobot neuron dan nilai ambang batas sehingga perceptron akan memberikan jawaban yang benar pada gambar visual preseden. Rosenblatt percaya bahwa fungsi yang dihasilkan akan baik dalam mengenali gambar visual yang diinginkan meskipun objek masukan tidak termasuk dalam preseden. Untuk alasan bionik, dia juga menemukan metode untuk memilih bobot dan ambang batas, yang tidak akan kita bahas lebih lanjut. Anggap saja pendekatannya berhasil dalam sejumlah masalah pengenalan dan memunculkan seluruh arah penelitian dalam algoritma pembelajaran berdasarkan jaringan saraf, kasus khusus di antaranya adalah perceptron.
Selanjutnya, berbagai generalisasi perceptron ditemukan, fungsi neuron menjadi lebih rumit: neuron sekarang tidak hanya dapat mengalikan bilangan masukan atau menjumlahkannya dan membandingkan hasilnya dengan ambang batas, tetapi juga menerapkan fungsi yang lebih kompleks dalam kaitannya dengan bilangan tersebut. Gambar 2 menunjukkan salah satu komplikasi neuron berikut:

Beras. 2 Diagram jaringan saraf.
Selain itu, topologi jaringan saraf bisa jadi jauh lebih kompleks daripada yang dipertimbangkan oleh Rosenblatt, misalnya:
Beras. 3. Diagram jaringan saraf Rosenblatt.
Komplikasi menyebabkan peningkatan jumlah parameter yang dapat disesuaikan selama pelatihan, tetapi pada saat yang sama meningkatkan kemampuan untuk menyesuaikan pola yang sangat kompleks. Penelitian di bidang ini sekarang berjalan dalam dua arah yang terkait erat - berbagai topologi jaringan dan berbagai metode konfigurasi sedang dipelajari.
Jaringan saraf saat ini tidak hanya sebagai alat untuk memecahkan masalah pengenalan pola, tetapi juga telah digunakan dalam penelitian tentang memori asosiatif dan kompresi gambar. Meskipun bidang penelitian ini sangat bersinggungan dengan masalah pengenalan pola, bidang ini mewakili cabang sibernetika yang terpisah. Bagi seorang pengenal saat ini, jaringan saraf tidak lebih dari sekumpulan pemetaan yang ditentukan secara parametrik dan sangat spesifik, yang dalam pengertian ini tidak memiliki keunggulan signifikan dibandingkan banyak model pembelajaran serupa lainnya yang akan dicantumkan secara singkat di bawah.
Sehubungan dengan penilaian terhadap peran jaringan saraf untuk pengenalan itu sendiri (yaitu, bukan untuk bionik, yang saat ini sangat penting), saya ingin mencatat hal-hal berikut: jaringan saraf, menjadi objek yang sangat kompleks untuk matematika. analisis, bila digunakan dengan benar, memungkinkan ditemukannya hukum-hukum yang sangat non-sepele dalam data. Kesulitan analisis mereka, secara umum, dijelaskan oleh strukturnya yang kompleks dan, sebagai konsekuensinya, kemungkinan yang hampir tidak ada habisnya untuk menggeneralisasi berbagai macam pola. Namun kelebihan ini, seperti yang sering terjadi, merupakan sumber potensi kesalahan dan kemungkinan pelatihan ulang. Seperti yang akan dibahas di bawah, pandangan ganda terhadap prospek model pembelajaran apa pun adalah salah satu prinsip pembelajaran mesin.
Arah pengakuan populer lainnya adalah aturan logis dan pohon keputusan. Dibandingkan dengan metode pengenalan yang disebutkan di atas, metode ini paling aktif menggunakan gagasan untuk mengekspresikan pengetahuan kita tentang bidang subjek dalam bentuk struktur yang mungkin paling alami (pada tingkat sadar) - aturan logis. Aturan logika dasar berarti pernyataan seperti “jika fitur yang tidak dapat diklasifikasikan ada di relasi X, maka fitur yang diklasifikasikan ada di relasi Y.” Contoh aturan dalam diagnosa medis adalah sebagai berikut: jika pasien berusia di atas 60 tahun dan sebelumnya pernah mengalami serangan jantung, maka jangan melakukan operasi - risiko hasil negatif tinggi.
Untuk mencari aturan logis dalam data, diperlukan dua hal: menentukan ukuran “informatif” aturan dan ruang aturan. Dan tugas mencari aturan kemudian berubah menjadi tugas pencacahan penuh atau sebagian dalam ruang aturan untuk menemukan aturan yang paling informatif. Definisi kandungan informasi dapat diperkenalkan dengan berbagai cara, dan kami tidak akan membahasnya secara mendalam, mengingat ini juga merupakan parameter tertentu dari model. Ruang pencarian ditentukan dengan cara standar.
Setelah menemukan aturan yang cukup informatif, tahap “merakit” aturan menjadi pengklasifikasi akhir dimulai. Tanpa membahas secara mendalam masalah yang muncul di sini (dan jumlahnya cukup banyak), kami akan mencantumkan 2 metode utama “perakitan”. Tipe pertama adalah daftar linier. Tipe kedua adalah pemungutan suara berbobot, ketika setiap aturan diberi bobot tertentu, dan objek ditetapkan oleh pengklasifikasi ke kelas yang memiliki jumlah aturan terbanyak yang dipilih.
Akibatnya, fase konstruksi aturan dan fase "perakitan" dilakukan bersama-sama dan, ketika menyusun pemungutan suara atau daftar berbobot, pencarian aturan pada bagian data kasus dipanggil berulang kali untuk memastikan kesesuaian yang lebih baik antara data dan model. .
Dalam artikel ini, saya ingin menyoroti beberapa hasil mendasar dari teori pembelajaran mesin sedemikian rupa sehingga konsepnya jelas bagi pembaca yang memiliki pengetahuan tentang masalah klasifikasi dan regresi. Ide untuk menulis artikel seperti itu menjadi semakin jelas di benak saya dengan setiap buku yang saya baca, di mana ide-ide tentang mesin pengajar untuk mengenali diceritakan seolah-olah dari tengah dan sama sekali tidak jelas siapa penulisnya. metode itu diandalkan saat mengembangkannya. Di sisi lain, ada sejumlah buku yang membahas tentang konsep dasar pembelajaran mesin, namun penyajian materi di dalamnya mungkin tampak terlalu rumit untuk dibaca pertama kali.Motivasi
Mari kita pertimbangkan masalah ini. Kami memiliki dua kelas apel - enak dan tidak enak, 1 dan 0. Apel memiliki karakteristik - warna dan ukuran. Warnanya akan berubah terus menerus dari 0 ke 1, mis. 0 - apel sepenuhnya hijau, 1 - sepenuhnya merah. Ukurannya bisa berubah dengan cara yang sama, 0 - apel kecil, 1 - besar. Kami ingin mengembangkan algoritma yang akan menerima warna dan ukuran sebagai masukan, dan mengeluarkan kelas apel - apakah itu enak atau tidak. Sangat diharapkan bahwa semakin sedikit jumlah kesalahan, semakin baik. Pada saat yang sama, kami memiliki daftar akhir yang berisi data historis mengenai warna, ukuran dan kelas apel. Bagaimana kita dapat mengatasi masalah seperti itu?Pendekatan logis
Saat memecahkan masalah kita, metode pertama yang mungkin terlintas dalam pikiran kita mungkin adalah ini: mari kita buat aturan seperti if-else secara manual dan, bergantung pada nilai warna dan ukuran, kita akan menetapkan kelas tertentu ke apel. Itu. kami memiliki prasyarat - warna dan ukuran, dan ada konsekuensinya - rasa apel. Cukup masuk akal bila hanya ada sedikit tanda dan ambang batas yang dapat dinilai secara langsung sebagai perbandingan. Namun mungkin saja kondisi yang jelas tidak dapat diperoleh, dan ambang batas mana yang harus diambil dari data tidak jelas, dan jumlah rambu mungkin akan bertambah di masa mendatang. Bagaimana jika dalam daftar data historis kami, kami menemukan dua apel dengan warna dan ukuran yang sama, tetapi yang satu ditandai enak dan yang lainnya tidak? Oleh karena itu, metode pertama kami tidak sefleksibel dan terukur seperti yang kami inginkan.Sebutan
Mari kita perkenalkan notasi berikut. Kami akan menyatakan apel ke-th sebagai . Pada gilirannya, masing-masing terdiri dari dua angka - warna dan ukuran. Kami akan menunjukkan fakta ini dengan sepasang angka: . Kami menyatakan kelas masing-masing apel ke -th sebagai . Daftar dengan data historis akan dilambangkan dengan huruf , panjang daftar ini adalah . Elemen ke-th dari daftar ini adalah nilai atribut apel dan kelasnya. Itu. . Kami juga akan menyebutnya sebagai sampel. Kami menggunakan huruf kapital untuk menunjukkan variabel yang dapat mengambil nilai atribut dan kelas tertentu. Mari kita perkenalkan konsep baru - aturan keputusan adalah fungsi yang mengambil warna dan ukuran sebagai masukan, dan mengembalikan label kelas sebagai keluaran:Pendekatan probabilistik
Mengembangkan gagasan metode logis dengan premis dan konsekuensi, mari kita bertanya pada diri sendiri - berapa probabilitas bahwa apel yang tidak termasuk dalam sampel kita akan enak, mengingat nilai warna dan ukuran yang diukur ? Dalam notasi teori probabilitas, pertanyaan tersebut dapat dituliskan sebagai berikut:Ungkapan ini dapat diartikan sebagai premis, sebagai konsekuensi, namun peralihan dari premis ke konsekuensi akan mengikuti hukum probabilistik, bukan hukum logis. Itu. Alih-alih tabel kebenaran dengan nilai Boolean 0 dan 1 untuk suatu kelas, akan ada nilai probabilitas yang berkisar dari 0 hingga 1. Terapkan rumus Bayes dan dapatkan ekspresi berikut:
Mari kita lihat sisi kanan ungkapan ini lebih terinci. Pengganda disebut probabilitas sebelumnya dan berarti probabilitas menemukan apel yang enak di antara semua kemungkinan apel. Ada kemungkinan apriori untuk menemukan apel yang tidak berasa. Kemungkinan ini mungkin mencerminkan pengetahuan pribadi kita tentang bagaimana apel yang enak dan tidak enak tersebar di alam. Misalnya, dari pengalaman masa lalu kita mengetahui bahwa 80% dari semua apel itu enak. Atau kita dapat memperkirakan nilai ini hanya dengan menghitung proporsi apel lezat dalam daftar kita dengan data historis S. Faktor berikutnya menunjukkan seberapa besar kemungkinan memperoleh nilai warna dan ukuran tertentu untuk apel kelas 1. Ekspresi ini disebut juga fungsi kemungkinan dan dapat terlihat seperti ini: beberapa distribusi tertentu, misalnya normal. Kami menggunakan penyebut sebagai konstanta normalisasi sehingga probabilitas yang diinginkan bervariasi dari 0 hingga 1. Tujuan akhir kami bukanlah mencari probabilitas, tetapi untuk mencari aturan penentu yang akan segera memberi kami kelas tersebut. Bentuk akhir dari aturan keputusan bergantung pada nilai dan parameter apa yang kita ketahui. Misalnya, kita hanya dapat mengetahui nilai probabilitas sebelumnya, dan nilai sisanya tidak dapat diperkirakan. Maka aturan yang menentukan adalah ini: tetapkan semua apel nilai kelas yang probabilitas apriorinya paling besar. Itu. jika kita mengetahui bahwa 80% apel di alam ini enak, maka kita memberi setiap apel kelas 1. Maka kesalahan kita akan menjadi 20%. Jika kita juga dapat memperkirakan nilai fungsi kemungkinan $p(X=x_m | Y=1)$, maka kita dapat mencari nilai probabilitas yang diinginkan menggunakan rumus Bayes seperti yang ditulis di atas. Aturan yang menentukan di sini adalah: beri label untuk kelas yang probabilitasnya maksimum:
Sebut saja aturan ini sebagai pengklasifikasi Bayesian. Karena kita berurusan dengan probabilitas, bahkan nilai probabilitas yang besar tidak menjamin bahwa apel tersebut tidak termasuk dalam kelas 0. Mari kita perkirakan probabilitas kesalahan pada sebuah apel sebagai berikut: jika aturan keputusan mengembalikan nilai kelas sama dengan 1 , maka peluang terjadinya kesalahan adalah dan sebaliknya:
Kami tertarik pada kemungkinan kesalahan pengklasifikasi tidak hanya pada contoh spesifik ini, tetapi secara umum untuk semua kemungkinan apel:
Ekspresi ini adalah nilai kesalahan yang diharapkan. Jadi, untuk memecahkan masalah awal, kita sampai pada pengklasifikasi Bayesian, tapi apa kekurangannya? Masalah utamanya adalah memperkirakan probabilitas bersyarat dari data. Dalam kasus kami, kami mewakili sebuah objek dengan sepasang angka - warna dan ukuran, namun dalam masalah yang lebih kompleks, dimensi fitur mungkin berkali-kali lipat lebih tinggi dan jumlah observasi dari daftar kami dengan data historis mungkin tidak cukup untuk memperkirakan objek tersebut. probabilitas variabel acak multidimensi. Selanjutnya, kita akan mencoba menggeneralisasi konsep kesalahan pengklasifikasi kita, dan juga melihat apakah mungkin untuk memilih pengklasifikasi lain untuk menyelesaikan masalah.
Kerugian kesalahan pengklasifikasi
Anggap saja kita sudah mempunyai aturan pengambilan keputusan. Kemudian dapat membuat dua jenis kesalahan - yang pertama adalah menetapkan objek ke kelas 0, yang kelas sebenarnya adalah 1, dan sebaliknya, untuk menetapkan objek ke kelas 1, yang kelas sebenarnya adalah 0. Dalam beberapa soal, ini penting untuk membedakan kasus-kasus tersebut. Misalnya, kita lebih menderita ketika apel yang diberi label enak ternyata tidak berasa dan sebaliknya. Kami memformalkan tingkat ketidaknyamanan kami dari ekspektasi yang mengecewakan dalam konsep. Secara umum, kami memiliki fungsi kerugian yang mengembalikan angka untuk setiap kesalahan pengklasifikasi. Biarlah menjadi label kelas yang nyata. Fungsi kerugian kemudian mengembalikan nilai kerugian untuk label kelas sebenarnya dan nilai aturan keputusan kita. Contoh penggunaan fungsi ini - kita mengambil dari sebuah apel dengan kelas yang diketahui, meneruskan apel tersebut sebagai input ke aturan keputusan kita, mendapatkan perkiraan kelas dari aturan keputusan, jika nilainya cocok, maka kita asumsikan agar pengklasifikasi tidak salah dan tidak ada kerugian, jika nilainya tidak cocok, maka jumlah kerugian akan dikatakan fungsi kitaRisiko bersyarat dan Bayesian
Sekarang kita memiliki fungsi kerugian dan mengetahui berapa banyak kerugian yang kita alami akibat kesalahan klasifikasi objek, alangkah baiknya jika kita memahami berapa banyak rata-rata kerugian yang kita alami, di banyak objek. Jika kita mengetahui nilai - peluang apel ke-enak, dengan mempertimbangkan nilai terukur warna dan ukuran, serta nilai sebenarnya dari kelas tersebut (misalnya, ambil apel dari sampel S, lihat di awal artikel), maka kita bisa memperkenalkan konsep risiko bersyarat. Risiko bersyarat adalah nilai rata-rata kerugian pada suatu objek menurut aturan yang menentukan:Dalam kasus klasifikasi biner kami, ternyata:
Di atas, kami menjelaskan aturan keputusan, yang menugaskan objek ke kelas yang memiliki nilai probabilitas tertinggi. Aturan ini memberikan kerugian rata-rata minimum (risiko Bayesian), oleh karena itu pengklasifikasi Bayesian optimal dalam hal risiko. fungsional yang kami perkenalkan. Artinya pengklasifikasi Bayesian memiliki kesalahan klasifikasi sekecil mungkin.
Beberapa fungsi kerugian yang khas
Salah satu fungsi kerugian yang paling umum adalah fungsi simetris, ketika kerugian dari jenis kesalahan pertama dan kedua adalah setara. Misalnya, fungsi kerugian 1-0 (kerugian nol-satu) didefinisikan sebagai berikut:Maka risiko bersyarat untuk a(x) = 1 hanyalah nilai probabilitas mendapatkan kelas 0 pada objek:
Demikian pula untuk a(x) = 0:
Fungsi kerugian 1-0 mengambil nilai 1 jika pengklasifikasi membuat kesalahan pada objek dan 0 jika tidak. Sekarang mari kita pastikan bahwa nilai errornya tidak sama dengan 1, melainkan ke fungsi lain Q, bergantung pada aturan keputusan dan label kelas sebenarnya:
Maka risiko bersyarat dapat dituliskan sebagai berikut:
Catatan tentang notasi
Teks sebelumnya ditulis menurut notasi yang dianut dalam buku Duda dan Hart. Dalam buku asli oleh V.N. Vapnik mempertimbangkan proses berikut: alam memilih objek berdasarkan distribusi $p(x)$, dan kemudian memberikan label kelas padanya sesuai dengan distribusi kondisional $p(y|x)$. Kemudian risiko (ekspektasi kerugian) didefinisikan sebagaiDimana fungsi yang kita coba perkirakan ketergantungannya tidak diketahui, adalah fungsi kerugian untuk nilai riil dan nilai fungsi kita. Notasi ini lebih jelas untuk memperkenalkan konsep berikutnya – risiko empiris.
Risiko empiris
Pada tahap ini, kami telah menemukan bahwa metode logis tidak cocok untuk kami, karena tidak cukup fleksibel, dan kami tidak dapat menggunakan pengklasifikasi Bayesian ketika terdapat banyak fitur, tetapi jumlah data pelatihan terbatas dan kami tidak dapat mengembalikan kemungkinan tersebut. Kita juga mengetahui bahwa pengklasifikasi Bayesian memiliki kesalahan klasifikasi sekecil mungkin. Karena kita tidak bisa menggunakan pengklasifikasi Bayesian, mari kita gunakan sesuatu yang lebih sederhana. Mari kita perbaiki beberapa kelompok fungsi parametrik H dan pilih pengklasifikasi dari kelompok ini.Contoh: misalkan himpunan semua fungsi berbentuk
Semua fungsi himpunan ini akan berbeda satu sama lain hanya dalam koefisiennya. Ketika kita memilih keluarga seperti itu, kita berasumsi bahwa dalam koordinat ukuran warna antara titik kelas 1 dan titik kelas 0 kita dapat menggambar garis lurus dengan koefisien sedemikian a. sedemikian rupa sehingga titik-titik dengan kelas yang berbeda terletak di sepanjang sisi garis lurus yang berbeda. Diketahui bahwa untuk garis jenis ini vektor koefisiennya normal terhadap garis tersebut. Sekarang kita melakukan ini - kita mengambil apel kita, mengukur warna dan ukurannya dan memplot titik dengan koordinat yang diperoleh pada grafik dalam sumbu ukuran warna. Selanjutnya, kita mengukur sudut antara titik ini dan vektor $w$. Kita perhatikan bahwa titik kita bisa terletak pada salah satu sisi garis lurus atau sisi lainnya. Maka sudut antara dan titik tersebut akan lancip atau tumpul, dan hasil kali skalarnya akan positif atau negatif. Hal ini mengarah pada aturan yang menentukan:
Setelah kita memperbaiki kelas fungsi $H$, muncul pertanyaan - bagaimana cara memilih fungsi dengan koefisien yang diperlukan? Jawabannya adalah - mari kita pilih fungsi yang meminimalkan risiko Bayesian $R()$. Sekali lagi, masalahnya adalah untuk menghitung nilai risiko Bayesian, Anda perlu mengetahui distribusi $p(x,y)$, tetapi distribusinya tidak diberikan kepada kami, dan tidak selalu mungkin untuk memulihkannya. Ide lainnya adalah meminimalkan risiko tidak pada semua objek yang mungkin ada, tetapi hanya pada sampel. Itu. meminimalkan fungsi:
Fungsi ini disebut risiko empiris. Pertanyaan selanjutnya adalah mengapa kami memutuskan bahwa dengan meminimalkan risiko empiris, kami juga meminimalkan risiko Bayesian? Izinkan saya mengingatkan Anda bahwa tugas praktis kita adalah membuat kesalahan klasifikasi sesedikit mungkin. Semakin sedikit kesalahan, semakin rendah risiko Bayesian. Pembenaran konvergensi risiko empiris ke risiko Bayesian dengan peningkatan volume data diperoleh pada tahun 70an oleh dua ilmuwan - V. N. Vapnik dan A. Ya.
Jaminan konvergensi. Kasus paling sederhana
Jadi, kami sampai pada kesimpulan bahwa pengklasifikasi Bayesian memberikan kesalahan sekecil mungkin, tetapi dalam banyak kasus kami tidak dapat melatihnya dan kami juga tidak dapat menghitung kesalahan (risiko). Namun, kita dapat menghitung perkiraan risiko Bayesian, yang disebut risiko empiris, dan mengetahui risiko empiris, pilih fungsi perkiraan yang akan meminimalkan risiko empiris. Mari kita lihat situasi paling sederhana ketika meminimalkan risiko empiris menghasilkan pengklasifikasi yang juga meminimalkan risiko Bayesian. Untuk kasus yang paling sederhana, kita harus membuat asumsi yang jarang dipenuhi dalam praktiknya, namun dapat dilonggarkan nantinya. Mari kita perbaiki kelas fungsi terbatas yang darinya kita akan memilih pengklasifikasi kita dan berasumsi bahwa fungsi sebenarnya yang digunakan alam untuk mengklasifikasikan apel kita berdasarkan rasa ada dalam rangkaian hipotesis terbatas ini: . Kami juga memiliki sampel yang diperoleh dari distribusi objek. Kami menganggap semua objek sampel terdistribusi secara merata secara independen (iid). Maka hal berikut ini akan menjadi kenyataanDalil
Dengan memilih suatu fungsi dari suatu kelas menggunakan minimalisasi risiko empiris, kita dijamin akan menemukan fungsi yang memiliki nilai risiko Bayesian yang kecil jika sampel yang kita gunakan untuk melakukan minimalisasi memiliki ukuran yang memadai.Apa yang dimaksud dengan “nilai kecil” dan “ukuran cukup”, lihat literatur di bawah.
Ide pembuktian
Berdasarkan kondisi teorema, kita memperoleh sampel dari distribusi, yaitu. proses pemilihan objek dari alam bersifat acak. Setiap kali kami mengumpulkan sampel, sampelnya akan berasal dari distribusi yang sama, tetapi objeknya mungkin berbeda. Ide utama dari pembuktiannya adalah kita bisa mendapatkan sampel yang buruk sehingga algoritma yang kita pilih dengan meminimalkan risiko empiris pada sampel ini akan buruk dalam meminimalkan risiko Bayesian, tetapi pada saat yang sama akan baik dalam meminimalkan risiko Bayesian. meminimalkan risiko empiris, tetapi kemungkinan mendapatkan sampel seperti itu kecil dan semakin besar ukuran sampel, probabilitas ini menurun. Teorema serupa ada untuk asumsi yang lebih realistis, namun kami tidak akan mempertimbangkannya di sini.Hasil praktis
Memiliki bukti bahwa fungsi yang ditemukan dengan meminimalkan risiko empiris tidak akan memiliki kesalahan besar pada data yang sebelumnya tidak teramati dengan ukuran sampel pelatihan yang memadai, kita dapat menggunakan prinsip ini dalam praktiknya, misalnya sebagai berikut - kita mengambil ekspresi:Dan kami mengganti fungsi kerugian yang berbeda, bergantung pada masalah yang dipecahkan. Untuk regresi linier:
Untuk regresi logistik:
Meskipun mesin vektor pendukung mempunyai motivasi geometris, mereka juga dapat dianggap sebagai masalah minimalisasi risiko empiris.
Kesimpulan
Banyak metode pembelajaran yang diawasi dapat dianggap, antara lain, sebagai kasus khusus dari teori yang dikembangkan oleh V. N. Vapnik dan A. Ya. Teori ini memberikan jaminan mengenai kesalahan pada sampel pengujian, asalkan terdapat ukuran sampel pelatihan yang memadai dan persyaratan tertentu untuk ruang hipotesis tempat kita mencari algoritme.Sastra yang digunakan
- Sifat Teori Pembelajaran Statistik, Vladimir N. Vapnik
- Klasifikasi Pola, Edisi ke-2, Richard O. Duda, Peter E. Hart, David G. Stork
- Memahami Pembelajaran Mesin: Dari Teori ke Algoritma, Shai Shalev-Shwartz, Shai Ben-David
Tag: Tambahkan tag