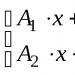Mari kita perhatikan contoh umum penerapan metode statistik dalam kedokteran. Pencipta obat menyarankan agar obat ini meningkatkan diuresis sebanding dengan dosis yang diminum. Untuk menguji hipotesis ini, mereka memberikan lima sukarelawan dosis obat yang berbeda.
Berdasarkan hasil observasi, dibuat grafik diuresis versus dosis (Gbr. 1.2A). Ketergantungan terlihat dengan mata telanjang. Para peneliti saling memberi selamat atas penemuan ini, dan dunia atas diuretik baru.
Faktanya, data hanya memungkinkan kami untuk menyatakan secara andal bahwa diuresis yang bergantung pada dosis diamati pada lima sukarelawan ini. Fakta bahwa ketergantungan ini akan terwujud pada semua orang yang memakai narkoba tidak lebih dari sekedar asumsi.
ZY

 Dengan
Dengan
kehidupan Tidak dapat dikatakan bahwa ini tidak berdasar - jika tidak, mengapa melakukan eksperimen?
Tapi obat itu mulai dijual. Semakin banyak orang yang meminumnya dengan harapan dapat meningkatkan produksi urin mereka. Jadi apa yang kita lihat? Kita melihat Gambar 1.2B, yang menunjukkan tidak adanya hubungan antara dosis obat dan diuresis. Lingkaran hitam menunjukkan data dari penelitian awal. Statistik mempunyai metode yang memungkinkan kita memperkirakan kemungkinan diperolehnya sampel yang “tidak representatif” dan bahkan membingungkan. Ternyata jika tidak ada hubungan antara diuresis dan dosis obat, “ketergantungan” yang diakibatkannya akan diamati pada sekitar 5 dari 1000 percobaan. Jadi, dalam kasus ini, para peneliti kurang beruntung. Sekalipun mereka menggunakan metode statistik paling canggih, hal itu tetap tidak dapat mencegah mereka melakukan kesalahan.
Kami memberikan contoh fiktif ini, tetapi sama sekali tidak jauh dari kenyataan, bukan untuk menunjukkan kesia-siaannya
pentingnya statistik. Dia berbicara tentang hal lain, tentang sifat probabilistik dari kesimpulannya. Akibat penerapan metode statistik, kita tidak memperoleh kebenaran hakiki, melainkan hanya perkiraan probabilitas suatu asumsi tertentu. Selain itu, setiap metode statistik didasarkan pada model matematikanya sendiri dan hasilnya benar sepanjang model tersebut sesuai dengan kenyataan.
Lebih lanjut tentang topik KEANDALAN DAN SIGNIFIKANSI STATISTIK:
- Perbedaan yang signifikan secara statistik dalam indikator kualitas hidup
- Populasi statistik. Karakteristik akuntansi. Konsep penelitian yang berkesinambungan dan selektif. Persyaratan data statistik dan penggunaan dokumen akuntansi dan pelaporan
- ABSTRAK. STUDI KEANDALAN INDIKASI TONOMETER UNTUK MENGUKUR TEKANAN INTRAOKULAR MELALUI KELOPAK MATA 2018, 2018
Tingkat signifikansi - ini adalah probabilitas bahwa kami menganggap perbedaannya signifikan, tetapi sebenarnya perbedaan tersebut acak.
Ketika kami menunjukkan bahwa perbedaannya signifikan pada tingkat signifikansi 5%, atau kapan R< 0,05 , maka yang kami maksud adalah probabilitas bahwa mereka tidak dapat diandalkan adalah 0,05.
Ketika kami menunjukkan bahwa perbedaannya signifikan pada tingkat signifikansi 1%, atau kapan R< 0,01 , maka yang kami maksud adalah probabilitas bahwa mereka tidak dapat diandalkan adalah 0,01.
Jika kita menerjemahkan semua ini ke dalam bahasa yang lebih formal, maka tingkat signifikansinya adalah kemungkinan menolak hipotesis nol, padahal hipotesis itu benar.
Kesalahan,terdiri dariyang satuapa yang kitaditolakhipotesis nolmeskipun benar, ini disebut kesalahan tipe 1.(Lihat Tabel 1)
Meja 1. Hipotesis nol dan alternatif serta kondisi pengujian yang mungkin.
Kemungkinan kesalahan seperti itu biasanya dilambangkan sebagai α. Intinya, kita harus menunjukkan dalam tanda kurung, bukan hal < 0,05 atau hal < 0,01, dan α < 0,05 atau < 0,01.
Jika kemungkinan kesalahannya adalah α , maka peluang pengambilan keputusan yang benar: 1-α. Semakin kecil α, semakin besar kemungkinan pengambilan keputusan yang benar.
Secara historis, dalam psikologi secara umum diterima bahwa tingkat signifikansi statistik terendah adalah tingkat 5% (p≤0.05): cukup adalah tingkat 1% (p≤0.01) dan yang tertinggi adalah tingkat 0.1% ( p≤0.001) , oleh karena itu, tabel nilai kritis biasanya berisi nilai kriteria yang sesuai dengan tingkat signifikansi statistik p≤0,05 dan p≤0,01, terkadang - p≤0,001. Untuk beberapa kriteria, tabel menunjukkan tingkat signifikansi yang tepat dari nilai empiris yang berbeda. Misalnya, untuk φ*=1,56 p=O,06.
Namun, hingga tingkat signifikansi statistik mencapai p=0,05, kita masih belum berhak menolak hipotesis nol.
Kami akan mematuhi aturan berikut untuk menolak hipotesis tidak ada perbedaan (Ho) dan menerima hipotesis perbedaan signifikansi statistik (H 1).
Aturan untuk menolak Ho dan menerima h1
Jika nilai empiris kriteria sama dengan nilai kritis p≤0,01 atau melebihinya, maka H 0 ditolak dan H 1 diterima.
Pengecualian : Uji tanda G, uji Wilcoxon T, dan uji Mann-Whitney U. Hubungan terbalik terjalin untuk mereka.

Beras. 4. Contoh “sumbu signifikansi” untuk kriteria Q Rosenbaum.
Nilai kritis kriteria ditetapkan sebagai Q o, o5 dan Q 0,01, nilai empiris kriteria sebagai Q em. Itu tertutup dalam elips.
Di sebelah kanan nilai kritis Q 0,01 terdapat “zona signifikansi” - ini mencakup nilai empiris yang melebihi Q 0,01 dan, oleh karena itu, tentu saja signifikan.
Di sebelah kiri nilai kritis Q 0,05, terdapat “zona tidak penting” - ini termasuk nilai empiris Q yang berada di bawah Q 0,05 dan, oleh karena itu, tentu saja tidak signifikan.
Kami melihatnya Q 0,05 =6; Q 0,01 =9; Q em. =8;
Nilai empiris kriteria tersebut berada pada kisaran antara Q 0,05 dan Q 0,01. Ini adalah zona “ketidakpastian”: kita sudah dapat menolak hipotesis tentang perbedaan yang tidak dapat diandalkan (H 0), tetapi kita belum dapat menerima hipotesis tentang keandalannya (H 1).
Namun dalam praktiknya, peneliti dapat menganggap perbedaan-perbedaan yang tidak termasuk dalam zona tidak penting dapat diandalkan, dengan menyatakan bahwa perbedaan-perbedaan tersebut dapat diandalkan pada saat yang sama. < 0,05, atau dengan menunjukkan tingkat signifikansi yang tepat dari nilai kriteria empiris yang diperoleh, misalnya: p=0,02. Dengan menggunakan tabel standar yang terdapat di semua buku teks metode matematika, hal ini dapat dilakukan sehubungan dengan kriteria Kruskal-Wallis H, χ 2 R Friedman, L Halaman, Fisher φ* .
Tingkat signifikansi statistik, atau nilai uji kritis, ditentukan secara berbeda ketika menguji hipotesis statistik terarah dan tidak terarah.
Dengan hipotesis statistik terarah, digunakan uji satu sisi, dengan hipotesis non-arah, digunakan uji dua sisi. Uji dua sisi lebih ketat karena menguji perbedaan dua arah, sehingga nilai empiris pengujian sebelumnya sesuai dengan tingkat signifikansi p. < 0,05, sekarang hanya sesuai dengan level p < 0,10.
Kita tidak perlu memutuskan sendiri apakah ia menggunakan kriteria satu sisi atau dua sisi. Tabel nilai kritis kriteria dipilih sedemikian rupa sehingga hipotesis terarah sesuai dengan kriteria satu sisi, dan hipotesis non-arah sesuai dengan kriteria dua sisi, dan nilai yang diberikan memenuhi persyaratan bahwa berlaku untuk masing-masingnya. Peneliti hanya perlu memastikan bahwa hipotesisnya sesuai makna dan bentuk dengan hipotesis yang diajukan dalam uraian masing-masing kriteria.
Jika Anda tidak bertindak, lingkungan tidak akan ada gunanya. (Shota Rustaveli)
Istilah dan konsep dasar statistik medis
Pada artikel ini kami akan menyajikan beberapa konsep statistik utama yang relevan ketika melakukan penelitian medis. Istilah-istilah tersebut dibahas secara lebih rinci dalam artikel-artikel terkait.
Variasi
Definisi. Derajat penyebaran data (nilai atribut) pada rentang nilai
Kemungkinan
Definisi. Probabilitas adalah derajat kemungkinan terjadinya suatu peristiwa tertentu dalam kondisi tertentu.
Contoh. Mari kita jelaskan pengertian istilah pada kalimat “Kemungkinan sembuh bila menggunakan obat Arimidex adalah 70%”. Peristiwanya adalah “pasien sembuh”, kondisi “pasien memakai Arimidex”, kemungkinannya 70% (secara kasar, dari 100 orang yang memakai Arimidex, 70 sembuh).
Probabilitas kumulatif
Definisi. Probabilitas Kumulatif untuk bertahan hidup pada waktu t sama dengan proporsi pasien yang hidup pada waktu tersebut.
Contoh. Jika dikatakan probabilitas kumulatif kelangsungan hidup setelah pengobatan selama lima tahun adalah 0,7, maka ini berarti dari kelompok pasien yang dipertimbangkan, 70% dari jumlah awal tetap hidup, dan 30% meninggal. Dengan kata lain, dari setiap seratus orang, 30 orang meninggal dalam 5 tahun pertama.
Waktu sebelum acara
Definisi. Waktu sebelum suatu peristiwa adalah waktu, yang dinyatakan dalam satuan tertentu, yang telah berlalu dari suatu titik waktu awal hingga terjadinya suatu peristiwa.
Penjelasan. Satuan waktu dalam penelitian kedokteran adalah hari, bulan, dan tahun.
Contoh umum waktu awal:
mulai memantau pasien
perawatan bedah
Contoh umum dari peristiwa yang dipertimbangkan:
perkembangan penyakit
terjadinya kekambuhan
kematian pasien
Mencicipi
Definisi. Porsi suatu populasi yang diperoleh melalui seleksi.
Berdasarkan hasil analisis sampel ditarik kesimpulan tentang keseluruhan populasi, yang hanya valid jika pemilihannya dilakukan secara acak. Karena secara praktis tidak mungkin untuk memilih suatu populasi secara acak, upaya harus dilakukan untuk memastikan bahwa sampel setidaknya mewakili populasi.
Sampel dependen dan independen
Definisi. Sampel dimana subjek penelitian direkrut secara independen satu sama lain. Alternatif sampel independen adalah sampel dependen (terhubung, berpasangan).
Hipotesa
Hipotesis dua sisi dan satu sisi
Pertama, mari kita jelaskan penggunaan istilah hipotesis dalam statistik.
Tujuan sebagian besar penelitian adalah untuk menguji kebenaran suatu pernyataan. Tujuan pengujian obat paling sering adalah untuk menguji hipotesis bahwa satu obat lebih efektif dibandingkan obat lain (misalnya, Arimidex lebih efektif daripada Tamoxifen).
Untuk memastikan ketelitian penelitian, pernyataan yang diverifikasi dinyatakan secara matematis. Misalnya, jika A adalah lama hidup pasien yang mengonsumsi Arimidex, dan T adalah lama hidup pasien yang mengonsumsi Tamoxifen, maka hipotesis yang diuji dapat ditulis sebagai A>T.
Definisi. Suatu hipotesis disebut dua sisi jika terdiri dari persamaan dua besaran.
Contoh hipotesis dua sisi: A=T.
Definisi. Suatu hipotesis disebut satu sisi (1-sisi) jika terdiri dari pertidaksamaan dua besaran.
Contoh hipotesis sepihak:
Data dikotomis (biner).
Definisi. Data dinyatakan hanya dengan dua nilai alternatif yang valid
Contoh: Pasien “sehat” - “sakit”. Edema "adalah" - "tidak".
Interval kepercayaan
Definisi. Selang kepercayaan suatu besaran adalah kisaran di sekitar nilai besaran yang di dalamnya terdapat nilai sebenarnya besaran tersebut (dengan tingkat kepercayaan tertentu).
Contoh. Biarkan kuantitas yang diteliti menjadi jumlah pasien per tahun. Rata-rata jumlahnya 500, dan selang kepercayaan 95% adalah (350, 900). Artinya, kemungkinan besar (dengan probabilitas 95%), setidaknya 350 dan tidak lebih dari 900 orang akan menghubungi klinik sepanjang tahun.
Penamaan. Singkatan yang sangat umum digunakan adalah: CI 95% adalah interval kepercayaan dengan tingkat kepercayaan 95%.
Keandalan, signifikansi statistik (P - level)
Definisi. Signifikansi statistik dari suatu hasil merupakan ukuran keyakinan terhadap “kebenaran” hasil tersebut.
Setiap penelitian dilakukan atas dasar hanya sebagian dari objeknya. Studi tentang efektivitas suatu obat dilakukan tidak berdasarkan semua pasien di planet ini, tetapi hanya pada kelompok pasien tertentu (tidak mungkin melakukan analisis berdasarkan semua pasien).
Misalkan, sebagai hasil analisis, diperoleh kesimpulan tertentu (misalnya, penggunaan Arimidex sebagai terapi yang memadai 2 kali lebih efektif daripada Tamoxifen).
Pertanyaan yang perlu ditanyakan adalah: “Seberapa besar Anda bisa mempercayai hasil ini?”
Bayangkan kita melakukan penelitian hanya berdasarkan dua pasien. Tentu saja, dalam hal ini, hasilnya harus diperlakukan dengan hati-hati. Jika sejumlah besar pasien yang diperiksa (nilai numerik dari “jumlah besar” tergantung pada situasinya), maka kesimpulan yang diambil sudah dapat dipercaya.
Jadi, derajat kepercayaan ditentukan oleh nilai tingkat p (p-value).
Tingkat p yang lebih tinggi berarti tingkat kepercayaan yang lebih rendah terhadap hasil yang diperoleh dari analisis sampel. Misalnya, tingkat p sebesar 0,05 (5%) menunjukkan bahwa kesimpulan yang diambil dari analisis kelompok tertentu hanyalah fitur acak dari objek tersebut dengan probabilitas hanya 5%.
Dengan kata lain, dengan probabilitas yang sangat tinggi (95%) kesimpulannya dapat diperluas ke semua objek.
Banyak penelitian menganggap 5% sebagai nilai tingkat p yang dapat diterima. Artinya jika misalnya p = 0,01 maka hasilnya dapat dipercaya, tetapi jika p = 0,06 maka tidak bisa.
Belajar
Studi prospektif adalah penelitian di mana sampel dipilih berdasarkan suatu faktor awal, dan beberapa faktor yang dihasilkan dianalisis dalam sampel tersebut.
Studi retrospektif adalah suatu penelitian di mana sampel dipilih berdasarkan suatu faktor yang dihasilkan, dan beberapa faktor awal dianalisis dalam sampel tersebut.
Contoh. Faktor awalnya adalah ibu hamil berusia muda/di atas 20 tahun. Faktor yang diakibatkan adalah berat badan anak lebih ringan/berat kurang dari 2,5 kg. Kami menganalisis apakah berat badan anak bergantung pada usia ibu.
Jika kita merekrut 2 sampel, satu sampel dengan ibu berusia di bawah 20 tahun, satu lagi dengan ibu berusia lebih tua, dan kemudian menganalisis massa anak di masing-masing kelompok, maka ini adalah penelitian prospektif.
Jika kita merekrut 2 sampel, satu sampel adalah ibu yang melahirkan anak dengan berat kurang dari 2,5 kg, sampel lainnya lebih berat, dan kemudian menganalisis usia ibu di setiap kelompok, maka ini adalah penelitian retrospektif (tentu saja, penelitian semacam itu hanya dapat dilakukan setelah percobaan selesai, yaitu semua anak telah lahir).
Keluaran
Definisi. Suatu fenomena, indikator atau tanda laboratorium yang signifikan secara klinis yang menjadi objek perhatian peneliti. Saat melakukan uji klinis, hasil berfungsi sebagai kriteria untuk menilai efektivitas intervensi terapeutik atau pencegahan.
Epidemiologi klinis
Definisi. Ilmu yang memungkinkan untuk memprediksi hasil tertentu untuk setiap pasien tertentu berdasarkan studi perjalanan klinis penyakit dalam kasus serupa, menggunakan metode ilmiah yang ketat dalam mempelajari pasien untuk memastikan keakuratan prediksi.
Kelompok
Definisi. Sekelompok peserta penelitian disatukan oleh beberapa ciri umum pada saat pembentukannya dan dipelajari dalam jangka waktu yang lama.
Kontrol
Kontrol sejarah
Definisi. Kelompok kontrol dibentuk dan diperiksa pada periode sebelum penelitian.
Kontrol paralel
Definisi. Kelompok kontrol terbentuk bersamaan dengan terbentuknya kelompok utama.
Korelasi
Definisi. Hubungan statistik antara dua karakteristik (kuantitatif atau ordinal), menunjukkan bahwa nilai yang lebih besar dari satu karakteristik dalam bagian kasus tertentu sesuai dengan nilai yang lebih besar - dalam kasus korelasi positif (langsung) - dari karakteristik lain atau lebih kecil nilai - dalam kasus korelasi negatif (terbalik).
Contoh. Ditemukan korelasi yang signifikan antara kadar trombosit dan leukosit dalam darah pasien. Koefisien korelasinya sebesar 0,76.
Koefisien risiko (RR)
Definisi. Rasio risiko adalah perbandingan peluang terjadinya suatu peristiwa (“buruk”) pada kelompok objek pertama dengan peluang terjadinya peristiwa yang sama pada kelompok objek kedua.
Contoh. Jika kemungkinan terkena kanker paru-paru pada bukan perokok adalah 20%, dan pada perokok - 100%, maka CR akan sama dengan seperlima. Dalam contoh ini, kelompok objek pertama adalah bukan perokok, kelompok kedua adalah perokok, dan terjadinya kanker paru-paru dianggap sebagai peristiwa yang “buruk”.
Jelas bahwa:
1) jika CR=1, maka peluang terjadinya suatu kejadian secara berkelompok adalah sama
2) jika KP>1, maka kejadian tersebut lebih sering terjadi pada objek kelompok pertama dibandingkan objek kelompok kedua
3) jika KR<1, то событие чаще происходит с объектами из второй группы, чем из первой
Meta-analisis
Definisi. DENGAN analisis statistik yang merangkum hasil beberapa penelitian yang menyelidiki masalah yang sama (biasanya efektivitas pengobatan, pencegahan, metode diagnostik). Studi pengumpulan memberikan sampel yang lebih besar untuk analisis dan kekuatan statistik yang lebih besar untuk studi gabungan. Digunakan untuk menambah bukti atau keyakinan terhadap suatu kesimpulan tentang efektivitas metode yang diteliti.
Metode Kaplan-Meier (perkiraan pengganda Kaplan-Meier)
Metode ini ditemukan oleh ahli statistik E.L. Kaplan dan Paul Meyer.
Metode tersebut digunakan untuk menghitung berbagai besaran yang berhubungan dengan waktu observasi seorang pasien. Contoh besaran tersebut:
kemungkinan pemulihan dalam waktu satu tahun saat menggunakan obat
kemungkinan kambuh setelah operasi dalam waktu tiga tahun setelah operasi
probabilitas kumulatif untuk bertahan hidup dalam lima tahun di antara pasien dengan kanker prostat setelah amputasi organ
Mari kita jelaskan keuntungan menggunakan metode Kaplan-Meier.
Nilai-nilai dalam analisis “konvensional” (tidak menggunakan metode Kaplan-Meier) dihitung berdasarkan pembagian interval waktu yang dipertimbangkan menjadi interval-interval.
Misalnya kita mempelajari peluang kematian seorang pasien dalam waktu 5 tahun, maka selang waktu tersebut dapat dibagi menjadi 5 bagian (kurang dari 1 tahun, 1-2 tahun, 2-3 tahun, 3-4 tahun, 4- 5 tahun), begitu dan selama 10 (masing-masing enam bulan), atau beberapa selang waktu lainnya. Hasil untuk partisi yang berbeda akan berbeda.
Memilih partisi yang paling tepat bukanlah tugas yang mudah.
Perkiraan nilai yang diperoleh dengan menggunakan metode Kaplan-Meier tidak bergantung pada pembagian waktu pengamatan menjadi beberapa interval, tetapi hanya bergantung pada waktu hidup masing-masing pasien.
Oleh karena itu, peneliti lebih mudah melakukan analisis, dan hasilnya seringkali lebih baik daripada hasil analisis “konvensional”.
Kurva Kaplan-Meier merupakan grafik kurva survival yang diperoleh dengan menggunakan metode Kaplan-Meier.
Model Cox
Model ini ditemukan oleh Sir David Roxby Cox (lahir 1924), seorang ahli statistik terkenal Inggris, penulis lebih dari 300 artikel dan buku.
Model Cox digunakan dalam situasi di mana besaran yang dipelajari dalam analisis kelangsungan hidup bergantung pada fungsi waktu. Misalnya, kemungkinan kambuh setelah t tahun (t=1,2,...) mungkin bergantung pada logaritma log waktu (t).
Keuntungan penting dari metode yang diusulkan oleh Cox adalah penerapan metode ini dalam banyak situasi (model tidak menerapkan batasan ketat pada sifat atau bentuk distribusi probabilitas).
Berdasarkan model Cox dapat dilakukan suatu analisis (disebut analisis Cox), yang hasilnya berupa nilai koefisien risiko dan interval kepercayaan untuk koefisien risiko.
Metode statistik nonparametrik
Definisi. Sekelompok metode statistik yang digunakan terutama untuk analisis data kuantitatif yang tidak membentuk distribusi normal, serta untuk analisis data kualitatif.
Contoh. Untuk mengidentifikasi signifikansi perbedaan tekanan sistolik pasien tergantung pada jenis pengobatan, kami akan menggunakan uji Mann-Whitney nonparametrik.
Tanda tangan (variabel)
Definisi. X ciri-ciri objek kajian (observasi). Ada karakteristik kualitatif dan kuantitatif.
Pengacakan
Definisi. Suatu metode pembagian objek penelitian secara acak ke dalam kelompok utama dan kelompok kontrol dengan menggunakan cara khusus (tabel atau penghitung angka acak, lempar koin, dan metode lain untuk menetapkan nomor kelompok secara acak pada observasi yang disertakan). Pengacakan meminimalkan perbedaan antar kelompok mengenai karakteristik yang diketahui dan tidak diketahui yang berpotensi mempengaruhi hasil yang diteliti.
Mempertaruhkan
Atributif- risiko tambahan dari hasil yang tidak menguntungkan (misalnya penyakit) karena adanya karakteristik tertentu (faktor risiko) pada subjek penelitian. Ini adalah bagian risiko berkembangnya suatu penyakit yang berhubungan dengan, dijelaskan oleh, dan dapat dihilangkan jika faktor risikonya dihilangkan.
Risiko relatif- rasio risiko kondisi buruk pada satu kelompok dengan risiko kondisi tersebut pada kelompok lain. Digunakan dalam penelitian prospektif dan observasional apabila kelompok telah dibentuk terlebih dahulu dan belum terjadi kondisi yang diteliti.
Ujian bergulir
Definisi. Suatu metode untuk memeriksa stabilitas, keandalan, kinerja (validitas) suatu model statistik dengan menghilangkan observasi secara berurutan dan menghitung ulang model tersebut. Semakin mirip model yang dihasilkan, semakin stabil dan andal model tersebut.
Peristiwa
Definisi. Hasil klinis yang diamati dalam penelitian, seperti terjadinya komplikasi, kekambuhan, pemulihan, atau kematian.
Stratifikasi
Definisi. M teknik pengambilan sampel di mana populasi seluruh partisipan yang memenuhi kriteria inklusi suatu penelitian dibagi terlebih dahulu menjadi beberapa kelompok (strata) berdasarkan satu atau lebih karakteristik (biasanya jenis kelamin, usia) yang berpotensi mempengaruhi hasil yang diinginkan, dan kemudian dari masing-masing karakteristik tersebut. kelompok ini ( strata) peserta direkrut secara independen ke dalam kelompok eksperimen dan kontrol. Hal ini memungkinkan peneliti untuk menyeimbangkan karakteristik penting antara kelompok eksperimen dan kelompok kontrol.
Tabel kontingensi
Definisi. Tabel frekuensi absolut (angka) pengamatan, kolom yang sesuai dengan nilai satu karakteristik, dan baris - dengan nilai karakteristik lain (dalam kasus tabel kontingensi dua dimensi). Nilai frekuensi absolut terletak di sel pada perpotongan baris dan kolom.
Mari kita beri contoh tabel kontingensi. Operasi aneurisma dilakukan pada 194 pasien. Tingkat keparahan edema pada pasien sebelum operasi diketahui.
|
Edema\ Hasil | |||
|---|---|---|---|
| tidak ada pembengkakan | 20 | 6 | 26 |
| pembengkakan sedang | 27 | 15 | 42 |
| edema yang parah | 8 | 21 | 29 |
| mj | 55 | 42 | 194 |
Dengan demikian, dari 26 pasien tanpa edema, 20 pasien selamat setelah operasi, dan 6 pasien meninggal. Dari 42 pasien dengan edema sedang, 27 pasien selamat, 15 meninggal, dan seterusnya.
Uji chi-kuadrat untuk tabel kontingensi
Untuk menentukan signifikansi (keandalan) perbedaan antara satu tanda dengan tanda lainnya (misalnya, hasil operasi tergantung pada tingkat keparahan edema), uji chi-kuadrat digunakan untuk tabel kontingensi:

Peluang
Misalkan peluang suatu kejadian sama dengan p. Maka peluang terjadinya peristiwa tersebut adalah 1-p.
Misalnya, jika peluang seorang pasien untuk tetap hidup setelah lima tahun adalah 0,8 (80%), maka peluang ia akan meninggal dalam jangka waktu tersebut adalah 0,2 (20%).
Definisi. Peluang adalah perbandingan peluang terjadinya suatu peristiwa dengan peluang tidak terjadinya peristiwa tersebut.
Contoh. Dalam contoh kita (tentang seorang pasien), peluangnya adalah 4, karena 0,8/0,2=4
Dengan demikian, kemungkinan sembuhnya 4 kali lebih besar dibandingkan kemungkinan meninggal.
Interpretasi nilai suatu besaran.
1) Jika Peluang=1, maka peluang terjadinya suatu peristiwa sama dengan peluang tidak terjadinya peristiwa tersebut;
2) jika Peluang >1, maka peluang terjadinya suatu peristiwa lebih besar daripada peluang tidak terjadinya peristiwa tersebut;
3) jika Kesempatan<1, то вероятность наступления события меньше вероятности того, что событие не произойдёт.
Rasio peluang
Definisi. Odds Ratio adalah perbandingan odds kelompok objek pertama dengan rasio odds kelompok objek kedua.
Contoh. Mari kita asumsikan bahwa baik pria maupun wanita menjalani pengobatan tertentu.
Peluang seorang pasien laki-laki tetap hidup setelah lima tahun adalah 0,6 (60%); kemungkinan dia akan meninggal dalam jangka waktu tersebut adalah 0,4 (40%).
Probabilitas serupa untuk perempuan adalah 0,8 dan 0,2.
Rasio odds dalam contoh ini adalah
Interpretasi nilai suatu besaran.
1) Jika odds rasio = 1, maka peluang kelompok pertama sama dengan peluang kelompok kedua
2) Apabila odds rasio >1, maka peluang kelompok pertama lebih besar dibandingkan peluang kelompok kedua
3) Jika rasio odds<1, то шанс для первой группы меньше шанса для второй группы
Dalam tabel hasil perhitungan statistik pada mata kuliah, diploma dan tesis magister psikologi, indikator “p” selalu ada.
Misalnya menurut tujuan penelitian Perbedaan tingkat kebermaknaan hidup antara remaja laki-laki dan perempuan dihitung.
|
Nilai rata-rata |
Tes Mann-Whitney U |
Tingkat signifikansi statistik (p) |
||
|
Putra (20 orang) |
Cewek-cewek (5 orang) |
|||
|
Sasaran |
28,9 |
35,2 |
17,5 |
0,027* |
|
Proses |
30,1 |
32,0 |
38,5 |
0,435 |
|
Hasil |
25,2 |
29,0 |
29,5 |
0,164 |
|
Pusat kendali - "Aku" |
20,3 |
23,6 |
0,067 |
|
|
Lokus Kendali - "Kehidupan" |
30,4 |
33,8 |
27,5 |
0,126 |
|
Kehidupan yang bermakna |
98,9 |
111,2 |
0,103 |
|
* - perbedaannya signifikan secara statistik (hal≤ 0,05)
Kolom sebelah kanan menunjukkan nilai “p” dan dari nilainya itulah kita dapat menentukan apakah perbedaan kebermaknaan hidup di masa depan antara anak laki-laki dan anak perempuan signifikan atau tidak. Aturannya sederhana:
- Jika tingkat signifikansi statistik “p” kurang dari atau sama dengan 0,05, maka kita menyimpulkan bahwa perbedaan tersebut signifikan. Pada tabel di bawah, perbedaan antara anak laki-laki dan perempuan cukup signifikan dalam kaitannya dengan indikator “Tujuan” – kebermaknaan hidup di masa depan. Untuk anak perempuan, angka ini secara statistik jauh lebih tinggi dibandingkan anak laki-laki.
- Jika tingkat signifikansi statistik “p” lebih besar dari 0,05, maka disimpulkan perbedaannya tidak signifikan. Pada tabel di bawah, perbedaan antara anak laki-laki dan perempuan tidak signifikan untuk semua indikator lainnya, kecuali indikator pertama.
Dari manakah tingkat signifikansi statistik “p” berasal?
Tingkat signifikansi statistik dihitung program statistik bersamaan dengan perhitungan kriteria statistik. Dalam program ini, Anda juga dapat menetapkan batas kritis untuk tingkat signifikansi statistik dan indikator terkait akan disorot oleh program.
Misalnya, dalam program STATISTICA, saat menghitung korelasi, Anda dapat menetapkan batas “p”, misalnya 0,05, dan semua hubungan yang signifikan secara statistik akan disorot dengan warna merah.
Jika kriteria statistik dihitung secara manual, maka tingkat signifikansi “p” ditentukan dengan membandingkan nilai kriteria yang dihasilkan dengan nilai kritis.
Apa yang ditunjukkan oleh tingkat signifikansi statistik “p”?
Semua perhitungan statistik merupakan perkiraan. Tingkat perkiraan ini menentukan “p”. Tingkat signifikansinya ditulis dalam desimal, misalnya 0,023 atau 0,965. Jika kita mengalikan angka ini dengan 100, kita mendapatkan indikator p sebagai persentase: 2,3% dan 96,5%. Persentase ini mencerminkan kemungkinan asumsi kita mengenai hubungan antara, misalnya, agresi dan kecemasan, salah.
Yaitu, koefisien korelasi 0,58 antara agresi dan kecemasan diperoleh pada tingkat signifikansi statistik 0,05 atau probabilitas kesalahan 5%. Apa sebenarnya maksudnya ini?
Korelasi yang kami identifikasi berarti bahwa pola berikut diamati dalam sampel kami: semakin tinggi agresivitas, semakin tinggi kecemasannya. Artinya, jika kita mengambil dua remaja, dan yang satu memiliki kecemasan yang lebih tinggi dibandingkan yang lain, maka dengan mengetahui korelasi positifnya, kita dapat mengatakan bahwa remaja tersebut juga akan memiliki agresivitas yang lebih tinggi. Tetapi karena segala sesuatu dalam statistik adalah perkiraan, maka dengan menyatakan ini, kami mengakui bahwa kami mungkin salah, dan kemungkinan kesalahannya adalah 5%. Artinya, dengan melakukan 20 kali perbandingan pada kelompok remaja ini, kita dapat melakukan satu kesalahan dalam memprediksi tingkat agresivitas, yaitu mengetahui kecemasan.
Tingkat signifikansi statistik mana yang lebih baik: 0,01 atau 0,05
Tingkat signifikansi statistik mencerminkan kemungkinan kesalahan. Oleh karena itu, hasil pada p=0,01 lebih akurat dibandingkan pada p=0,05.
Dalam penelitian psikologis, dua tingkat signifikansi statistik hasil yang dapat diterima diterima:
p=0,01 - keandalan yang tinggi dari hasil analisis komparatif atau analisis hubungan;
p=0,05 - akurasi yang cukup.
Saya harap artikel ini akan membantu Anda menulis makalah psikologi sendiri. Jika Anda memerlukan bantuan, silakan hubungi kami (semua jenis pekerjaan di bidang psikologi; perhitungan statistik).
Signifikansi statistik
Hasil yang diperoleh dengan menggunakan prosedur penelitian tertentu disebut signifikan secara statistik, jika kemungkinan terjadinya secara acak sangat kecil. Konsep ini dapat diilustrasikan dengan contoh melempar koin. Misalkan sebuah koin dilempar sebanyak 30 kali; Kepala muncul 17 kali dan ekor muncul 13 kali. Adalah penting penyimpangan hasil ini dari yang diharapkan (15 kepala dan 15 ekor), atau apakah penyimpangan ini acak? Untuk menjawab pertanyaan ini, Anda dapat, misalnya, melempar koin yang sama berkali-kali, 30 kali berturut-turut, dan sekaligus mencatat berapa kali rasio “kepala” dan “ekor” 17:13 diulang. Analisis statistik menyelamatkan kita dari proses yang membosankan ini. Dengan bantuannya, setelah 30 pelemparan koin pertama, Anda dapat memperkirakan kemungkinan jumlah kemunculan acak 17 “kepala” dan 13 “ekor”. Penilaian seperti ini disebut pernyataan probabilistik.
Dalam literatur ilmiah tentang psikologi industri-organisasi, pernyataan probabilistik dalam bentuk matematika dilambangkan dengan ekspresi R(kemungkinan)< (менее) 0,05 (5 %), которое следует читать как «вероятность менее 5 %». В примере с киданием монеты это утверждение будет означать, что если исследователь проведет 100 опытов, каждый раз кидая монету по 30 раз, то он может ожидать случайного выпадения комбинации из 17 «орлов» и 13 «решек» менее, чем в 5 опытах. Этот результат будет сочтен статистически значимым, поскольку в индустриально-организационной психологии уже давно приняты стандарты статистической значимости 0,05 и 0,01 (P< 0,01). Fakta ini penting untuk memahami literatur, namun jangan diartikan bahwa tidak ada gunanya melakukan observasi yang tidak memenuhi standar ini. Yang disebut hasil penelitian tidak signifikan (pengamatan yang diperoleh secara kebetulan) lagi satu sampai lima kali dari 100) bisa sangat berguna dalam mengidentifikasi tren dan sebagai panduan untuk penelitian di masa depan.
Perlu juga dicatat bahwa tidak semua psikolog setuju dengan standar dan prosedur tradisional (misalnya, Cohen, 1994; Sauley & Bedeian, 1989). Permasalahan terkait pengukuran sendiri merupakan topik utama pekerjaan banyak peneliti, mempelajari keakuratan metode pengukuran dan asumsi yang mendasari metode dan standar yang ada, serta pengembangan dokter dan instrumen baru. Mungkin suatu saat nanti, penelitian mengenai kekuatan ini akan membawa perubahan pada standar tradisional untuk menilai signifikansi statistik, dan perubahan ini akan diterima secara luas. (Divisi Kelima American Psychological Association adalah sekelompok psikolog yang mengkhususkan diri dalam studi penilaian, pengukuran, dan statistik.)
Dalam laporan penelitian, pernyataan probabilistik seperti R< 0,05, karena beberapa statistik, yaitu bilangan yang diperoleh sebagai hasil serangkaian prosedur komputasi matematis tertentu. Konfirmasi probabilistik diperoleh dengan membandingkan statistik tersebut dengan data dari tabel khusus yang diterbitkan untuk tujuan ini. Dalam penelitian psikologi industri-organisasi, statistik seperti r, F, t, r>(baca “chi persegi”) dan R(baca "jamak" R"). Dalam setiap kasus, statistik (satu angka) yang diperoleh dari analisis serangkaian observasi dapat dibandingkan dengan angka-angka dari tabel yang dipublikasikan. Setelah itu, Anda dapat merumuskan pernyataan probabilistik tentang peluang diperolehnya bilangan tersebut secara acak, yaitu menarik kesimpulan tentang pentingnya pengamatan.
Untuk memahami kajian-kajian yang diuraikan dalam buku ini, cukup memiliki pemahaman yang jelas tentang konsep signifikansi statistik dan belum tentu mengetahui cara penghitungan statistik yang disebutkan di atas. Namun, akan bermanfaat jika membahas satu asumsi yang mendasari seluruh prosedur ini. Ini adalah asumsi bahwa semua variabel yang diamati berdistribusi normal. Selain itu, ketika membaca laporan penelitian psikologi industri-organisasi, sering muncul tiga konsep lain yang memainkan peran penting - pertama, korelasi dan komunikasi korelasional, kedua, variabel determinan/prediktif dan “ANOVA” (analisis varians), di - ketiga, sekelompok metode statistik dengan nama umum “meta-analisis”.