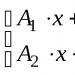Ada dua alasan utama ketertarikan pada jaringan saraf kuantum. Salah satunya melibatkan argumen bahwa proses kuantum mungkin memainkan peran penting dalam fungsi otak. Misalnya, Roger Penrose telah mengajukan berbagai argumen bahwa hanya fisika baru yang menyatukan mekanika kuantum dengan relativitas umum yang dapat menggambarkan fenomena seperti pemahaman dan kesadaran. Namun, pendekatannya tidak ditujukan pada jaringan saraf itu sendiri, melainkan pada struktur intraseluler seperti mikrotubulus. Alasan lainnya terkait dengan pesatnya pertumbuhan komputasi kuantum, yang ide utamanya dapat ditransfer ke neurocomputing, yang akan membuka kemungkinan baru bagi mereka.
Sistem saraf kuantum dapat mengatasi beberapa masalah sulit yang penting untuk komputasi kuantum karena sifat analognya dan kemampuannya untuk belajar dari sejumlah contoh yang terbatas.
Apa yang bisa kita harapkan dari jaringan saraf kuantum? Saat ini, jaringan saraf kuantum memiliki keunggulan sebagai berikut:
Kapasitas memori eksponensial;
Performa lebih baik dengan lebih sedikit neuron tersembunyi;
Pembelajaran cepat;
Penghapusan bencana lupa karena tidak adanya gangguan gambar;
Memecahkan masalah yang tidak dapat dipisahkan secara linier dengan jaringan satu lapis;
Kurangnya koneksi;
Kecepatan pemrosesan data tinggi (10 10 bit/s);
Miniatur (10 11 neuron/mm 3);
Stabilitas dan keandalan yang lebih tinggi;
Manfaat potensial dari jaringan saraf kuantum inilah yang terutama memotivasi pengembangannya.
Neuron kuantum
Sinapsis berkomunikasi antar neuron dan mengalikan sinyal masukan dengan angka yang mencirikan kekuatan koneksi - bobot sinapsis. Penambah melakukan penambahan sinyal yang datang melalui koneksi sinaptik dari neuron lain dan sinyal masukan eksternal. Konverter mengimplementasikan fungsi satu argumen, keluaran dari penambah, menjadi beberapa nilai keluaran neuron. Fungsi ini disebut fungsi aktivasi neuron.
Dengan demikian, neuron dijelaskan secara lengkap melalui bobot dan fungsi aktivasinya F. Setelah menerima sekumpulan angka (vektor) sebagai masukan, neuron menghasilkan sejumlah tertentu sebagai keluaran.
Fungsi aktivasi bisa bermacam-macam jenisnya. Opsi yang paling banyak digunakan ditunjukkan pada tabel (Tabel 2).
Tabel 2: Daftar fungsi aktivasi neuron
|
Nama |
Rentang nilai |
|
|
Ambang |
||
|
Ikonik |
|
|
|
Sigmoid |
|
|
|
Semilinier |
|
|
|
Linier |
||
|
Basis radial |
||
|
Semilinear dengan saturasi |
 |
|
|
Linier dengan saturasi |
 |
|
|
Garis singgung hiperbolik |
|
|
|
Segitiga |
|
Definisi Neuron Kuantum diberikan sebagai berikut:
Ia menerima sinyal masukan (data awal atau sinyal keluaran dari neuron SSP lainnya) melalui beberapa saluran masukan. Setiap sinyal masukan melewati sambungan yang memiliki intensitas (atau bobot) tertentu; bobot ini sesuai dengan aktivitas sinaptik neuron. Setiap neuron memiliki nilai ambang tertentu yang terkait dengannya. Jumlah input tertimbang dihitung, nilai ambang batas dikurangi darinya, dan hasilnya adalah jumlah aktivasi neuron (juga disebut potensi pasca-sinaptik neuron - PSP).
Sinyal aktivasi diubah menggunakan fungsi aktivasi (atau fungsi transfer) untuk menghasilkan keluaran neuron (Gambar 1).

Gambar 1
Model matematika dari neuron kuantum, di mana matriks bertindak berdasarkan operator yang dapat mengimplementasikan jaringan sel kuantum.
Misalnya: Proses pembelajaran neuron kuantum. = - operator identitas: .
Aturan pembelajaran kuantum diberikan dalam analogi dengan kasus klasik, sebagai berikut: , dimana adalah keluaran yang diinginkan. Aturan pembelajaran ini membawa neuron kuantum ke keadaan yang diinginkan untuk digunakan untuk pembelajaran. Dengan mengambil selisih antara kuadrat keluaran aktual dan yang diinginkan untuk modul, kita melihat bahwa:

Seluruh jaringan dapat dirakit dari elemen primitif menggunakan aturan standar arsitektur ANN.
Perbandingan data simulasi molekul hidrogen menggunakan komputer kuantum dengan nilai eksperimen. Sumbu horizontal adalah jarak antara atom hidrogen dalam molekul.
Sebuah tim fisikawan Inggris-Amerika, termasuk para ahli dari Google dan Universitas California, telah melakukan eksperimen pertama pada pemodelan kuantum molekul hidrogen yang dapat diskalakan. Dalam karyanya, penulis menggunakan komputer kuantum dua qubit dan melakukannya tanpa kompilasi algoritma awal yang intensif sumber daya. Studi ini dipublikasikan di jurnal Tinjauan Fisik X, blog Google menjelaskannya secara singkat.
Eksperimen ini didasarkan pada algoritma variasional untuk mencari solusi eigen menggunakan komputer kuantum (VQE), yang menurut para ilmuwan, adalah jaringan saraf kuantum. Seperti jaringan saraf lainnya, jaringan saraf ini berisi banyak parameter variabel yang dapat dipilih menggunakan pelatihan, tetapi jaringan saraf tradisional memodelkan sistem klasik, dan jaringan saraf kuantum, masing-masing, memodelkan sistem kuantum.
Dengan menggunakan metode ini, para ilmuwan menghitung bagaimana energi molekul hidrogen (H 2) berubah bergantung pada jarak antara atom hidrogen di dalamnya. Perhitungan ini adalah kasus khusus untuk memecahkan masalah struktur elektronik molekul. Dengan mengetahui bagaimana elektron tersusun dalam keadaan dasar suatu molekul, kita dapat memperkirakan kecepatan terjadinya reaksi kimia. Namun hal ini memerlukan perhitungan energi yang presisi tinggi. Ketika jumlah atom dalam suatu molekul meningkat, waktu yang dibutuhkan untuk perhitungan pada komputer klasik meningkat secara eksponensial. Seperti yang dijelaskan dalam blog Google, penghitungan energi keadaan dasar metana (CH 4) memerlukan waktu satu detik, etana (C 2 H 6) memerlukan waktu satu menit, dan propana (C 3 H 8) memerlukan waktu penghitungan sepanjang hari.
Sistem ini menggunakan qubit superkonduktor yang didinginkan hingga suhu 20 miliklvin. Setiap qubit terdiri dari interferometer kuantum superkonduktor (dikenal sebagai SQUID) dan kapasitor.

Skema perhitungan. Di sebelah kiri adalah foto mikro qubit, intinya adalah operasi logis yang dilakukan pada qubit.
P. J. J.O'Malley dkk. / Fis. Putaran. X, 2016
Penulis membandingkan hasil perhitungan menggunakan VQE dengan data eksperimen dan algoritma kuantum lainnya. Menurut fisikawan, berkat pelatihan, kesalahan sistematis yang terkait dengan peralatan yang tidak sempurna dapat dihilangkan dan memperoleh hasil yang mendekati data eksperimen. Para ilmuwan berharap ketahanan terhadap kesalahan seperti itu akan membantu menghindari salah satu masalah yang dihadapi dalam penerapan komputer kuantum di masa depan.
Seperti yang dijawab oleh para fisikawan, ketika teknologi ditingkatkan dan sistem multiqubit diciptakan, perhitungan serupa dapat dilakukan untuk molekul yang lebih kompleks. Misalnya, seratus qubit saja sudah cukup untuk mensimulasikan proses fiksasi nitrogen, yang memungkinkan bakteri menghasilkan pupuk dari udara tipis. Mungkin ini akan memperbaiki metode sintesis pupuk nitrogen yang ada.
Meskipun komputer kuantum sekarang merupakan sistem dengan sejumlah kecil qubit (-), fisikawan sudah menggunakannya untuk mensimulasikan proses berenergi tinggi.
Vladimir Korolev
2 Dasar-Dasar Komputasi Kuantum Qubit Qubit Satuan informasi kuantum adalah qubit Satuan informasi kuantum adalah qubit Qubit dapat dianggap sebagai sistem dengan 2 keadaan, mis. putaran 1/2 atau sistem dua tingkat. Qubit dapat dianggap sebagai sistem dengan 2 status, mis. putaran 1/2 atau sistem dua tingkat. Keadaan qubit dijelaskan oleh vektor 2 komponen: Keadaan qubit dijelaskan oleh vektor 2 komponen:
3 Dasar-dasar komputasi kuantum Gerbang kuantum Gerbang kuantum adalah analog dari operasi Boolean AND, OR, NOT, dll. Gerbang kuantum adalah analog dari operasi Boolean AND, OR, NOT, dll. Gerbang kuantum yang bekerja pada n qubit adalah operator kesatuan. Gerbang kuantum yang bekerja pada n qubit adalah operator kesatuan.

4 Algoritma kuantum Algoritma Simon untuk mencari periode suatu fungsi Algoritma Simon untuk mencari periode suatu fungsi Algoritma Shor untuk faktorisasi prima Algoritma Shor untuk faktorisasi prima Algoritma pencarian Grover Algoritma pencarian Grover Algoritma Deutsch Jos Algoritma Deutsch Jos



7 Algoritma Shor: langkah utama 1. Pilih sisa acak a modulo N 2. Periksa FPB(a, N)=1 3. Tentukan orde r dari sisa a modulo N 4. Jika r genap maka hitung GCD (a r/ 2 - 1 , N) Definisi: r minimum sehingga r 1 (mod N) disebut orde modulo N. Orde tersebut adalah periode dari fungsi f(x)=a x (mod N)










17 Memori asosiatif kuantum Jaringan asosiatif kuantum Perusha (2000) Jaringan asosiatif kuantum Perusha (2000) Berdasarkan Model Hopfield Berdasarkan Model Hopfield Generalisasi berkelanjutan dari Hamiltonian Hopfield Generalisasi berkelanjutan dari prinsip Holografik Hamiltonian Hopfield Prinsip holografik Prosedur pemeriksaan melalui dua- titik Fungsi Green Prosedur pemeriksaan melalui dua titik eksak Fungsi Green Runtuhnya fungsi gelombang sebagai konvergensi terhadap penarik Runtuhnya fungsi gelombang sebagai konvergensi terhadap penarik

18 Jaringan saraf kuantum Jaringan saraf kuantum (Berman et al, 2002) Jaringan saraf kuantum (Berman et al, 2002) Dirancang untuk menghitung tingkat keterjeratan kuantum Dirancang untuk menghitung tingkat keterjeratan kuantum Bekerja dalam waktu Bekerja dalam waktu Adalah umpan- jaringan maju Merupakan jaringan feed-forward Terdiri dari objek kuantum dua tingkat dan osilator linier Terdiri dari objek kuantum dua tingkat dan osilator linier


20 Memori asosiatif kuantum Quantum AP Ventura (1998, 2000, 2003) Quantum AP Ventura (1998, 2000, 2003) Berdasarkan algoritma Grover Berdasarkan algoritma Grover m vektor biner berdimensi n diingat m vektor biner berdimensi n diingat Kuantum khusus algoritma pembelajaran memberikan operator PA Algoritme pembelajaran kuantum khusus memberikan operator P Memiliki kapasitas eksponensial ~2 n Memiliki kapasitas eksponensial ~2 n


Kutipan dari pekerjaan
Kementerian pendidikan Dan sains Rusia Federasi
Institusi pendidikan negara di wilayah Moskow
Internasional universitas alam, masyarakat dan orang "Duna"
Magisterskitulah pekerjaannya
Subjek Jaringan saraf kuantum dalam proses pembelajaran dan kontrol
DENGANmurid Afanasyeva Olga Aleksandrovna
Anotasi
Karya ini dikhususkan untuk analisis jaringan saraf kuantum (QNN) dan aplikasi praktisnya.
Pemecahan masalah ini terkait erat dengan pengembangan metode pemrograman kuantum dan merupakan kepentingan teoritis dan praktis untuk merancang proses pengendalian cerdas yang kuat dalam kondisi risiko dan situasi pengendalian yang tidak terduga, dengan mempertimbangkan efek kuantum dalam pembentukan informasi. proses pengorganisasian diri dari basis pengetahuan.
Untuk mencapai tujuan ini, literatur penulis asing dipelajari, contoh penggunaan QNS dalam proses manajemen dipertimbangkan.
Hasil pekerjaannya adalah analisis komparatif antara neuron klasik dan kuantum. Operator kuantum baru seperti superposisi, korelasi kuantum, dan interferensi diusulkan. QNN memungkinkan Anda melihat ruang pencarian dan pelatihan, meningkatkan akurasi dan ketahanan proses perkiraan sinyal pembelajaran.
Pekerjaan itu dilakukan di bawah pengawasan ilmiah Dr. Phys.-Math. Sains, Profesor S.V. Ulyanov di Institut Analisis Sistem dan Manajemen Universitas Internasional Alam, Masyarakat dan Manusia “Dubna”.
- Perkenalan
- 1 . Pernyataan masalah
- 1.1 Tujuan
- 1.2 Data awal
- 1.3 Komponen penelitian
- 2 . Komponen ilmiah
- 2.1 Arsitektur Jaringan Syaraf Kuantum
- 2.2 Mengapa Jaringan Neural Kuantum menarik
- 2.3 Neuron kuantum
- 2.4 Pembangunan Jaringan Syaraf Kuantum
- 2.5 Komputasi kuantum
- 2.6 model KNS
- 2.7 Keadaan kuantum dan representasinya
- 3 . pelatihan SSP
- 3.2 Perceptron satu lapis dan multi lapis
- 3.2.1 Perceptron lapisan tunggal. Pendidikan
- 3.2.2 Perceptron berlapis-lapis. Pelatihan Perceptron Multilapis
- 3.4 Algoritma genetika. Masalah klasik penjual keliling
- 4 . Manajemen objek otomatis
- 4.1 Objek kendali
- 4.2 Robotika sebagai arah Kecerdasan Buatan
- 4.2.1 Diagram blok umum robot
- 4.2.2 Model konseptual
- 4.2 Kontrol register putaran kuantum yang efisien. Kriptografi dan teleportasi kuantum
- 5 . Bagian praktis. Contoh Jaringan Syaraf Kuantum
- 5.1 Pendulum terbalik
- 5.2 Kompresi gambar
- 5.3 Pengkodean alfabet
- 6 Perangkat ALAT JARINGAN SARAF MATLAB. Jaringan Kohonen
- Kesimpulan
- Referensi
- Perkenalan
- Saat ini, seperti seratus tahun yang lalu, tidak ada keraguan bahwa otak bekerja lebih efisien dan dengan cara yang berbeda secara fundamental dibandingkan mesin komputasi mana pun yang diciptakan manusia. Fakta inilah yang selama bertahun-tahun telah memotivasi dan memandu pekerjaan para ilmuwan di seluruh dunia untuk menciptakan dan mempelajari jaringan saraf tiruan.
- Jaringan Syaraf Tiruan (JST) memiliki beberapa fitur menarik, seperti pemrosesan terdistribusi paralel, toleransi kesalahan, dan kemampuan untuk mempelajari dan menggeneralisasi pengetahuan yang diperoleh. Properti generalisasi mengacu pada kemampuan ANN untuk menghasilkan keluaran yang benar untuk sinyal masukan yang tidak diperhitungkan selama proses pembelajaran. Kedua properti ini menjadikan ANN sebagai sistem pemrosesan informasi yang memecahkan masalah multidimensi kompleks yang berada di luar kemampuan teknik lainnya. Namun, ANN juga menghadapi banyak tantangan, termasuk kurangnya aturan untuk arsitektur optimal deterministik, kapasitas memori yang terbatas, waktu pelatihan yang lama, dan lain-lain.
- Jaringan Syaraf Tiruan telah dipraktekkan dimanapun diperlukan untuk memecahkan masalah peramalan, klasifikasi atau pengendalian. Keberhasilan yang mengesankan ini disebabkan oleh beberapa alasan:
- 1. Kemungkinan yang kaya. Jaringan saraf adalah teknik pemodelan yang sangat kuat yang dapat mereproduksi ketergantungan yang sangat kompleks. Selama bertahun-tahun, pemodelan linier telah menjadi metode pemodelan yang dominan di sebagian besar bidang karena prosedur optimasi telah dikembangkan dengan baik untuk metode tersebut. Dalam permasalahan di mana pendekatan linier tidak memuaskan (dan jumlahnya cukup banyak), model linier memiliki kinerja yang buruk. Selain itu, jaringan saraf mengatasi “kutukan dimensi”, yang tidak memungkinkan pemodelan ketergantungan linier dalam kasus sejumlah besar variabel.
- 2.Mudah digunakan. Jaringan saraf belajar dari contoh. Pengguna jaringan saraf memilih data yang representatif dan kemudian menjalankan algoritma pembelajaran yang secara otomatis mempelajari struktur data. Dalam hal ini, pengguna tentu saja diharuskan memiliki seperangkat pengetahuan heuristik tentang cara memilih dan menyiapkan data, memilih arsitektur jaringan yang diinginkan dan menafsirkan hasilnya, tetapi tingkat pengetahuan yang diperlukan untuk keberhasilan penggunaan jaringan saraf jauh lebih sederhana dibandingkan, misalnya, ketika menggunakan metode statistik tradisional.
- Di bidang ANN, beberapa pionir diperkenalkan kuantum komputasi menjadi diskusi serupa seperti neural kuantum perhitungan, Jaringan Syaraf Kuantum Terserap, Memori Asosiatif Kuantum, dan Pembelajaran Paralel. Mereka membangun landasan untuk mengeksplorasi lebih jauh komputasi kuantum di ANN. Dalam prosesnya, bidang jaringan saraf tiruan bermunculan, berdasarkan konsep dan metode teoretis kuantum. Mereka disebut Jaringan Syaraf Kuantum.
- 1. Pernyataan masalah
1.1 Tujuan
Penelitian dan analisis Quantum Neural Networks, aplikasi praktisnya.
Bidang penelitian pekerjaan
· Identifikasi keunggulan jaringan saraf kuantum dibandingkan jaringan klasik.
· Pertimbangkan contoh penggunaan jaringan saraf kuantum dalam proses kontrol cerdas.
· Mensimulasikan pengoperasian neuron kuantum pada komputer klasik.
· Memodelkan jaringan clustering data di MATLAB.
· Perhatikan contoh spesifik dari robotika (robot manipulator).
1.2 Data awal
· Buku sembilan volume tentang komputasi kuantum dan pemrograman kuantum, diterbitkan oleh Universitas Milan, penulis Ulyanov S.V.
· Monograf oleh Nilsson, 2006.
· Situs web www.qcoptimizer.com.
1.3 Komponen penelitian
Penelitian tersebut berkaitan dengan teknologi inovatif untuk pengembangan jaringan saraf kuantum di bidang sistem kendali cerdas dengan pembelajaran. Pemecahan masalah ini terkait erat dengan pengembangan metode pemrograman kuantum dan merupakan kepentingan teoritis dan praktis untuk merancang proses pengendalian cerdas yang kuat dalam kondisi risiko dan situasi pengendalian yang tidak terduga, dengan mempertimbangkan efek kuantum dalam pembentukan informasi. proses pengorganisasian diri dari basis pengetahuan.
2. Komponen ilmiah
2.1 Arsitektur Jaringan Syaraf Kuantum
Jaringan saraf kuantum adalah bidang yang sedang berkembang dan merupakan kombinasi dari jaringan saraf klasik dan komputasi kuantum.
Beberapa sistem mungkin dipanggil saraf, jika memungkinkan untuk mengidentifikasi setidaknya satu saraf. Sistem saraf adalah saraf kuantum sistem jika mampu diimplementasikan komputasi kuantum.
Ada beberapa pendekatan berbeda terhadap apa yang disebut jaringan saraf kuantum. Berbagai peneliti menggunakan analogi mereka sendiri untuk membangun hubungan antara mekanika kuantum dan jaringan saraf tiruan. Beberapa konsep dasar dari kedua bidang tersebut dirangkum dalam Tabel 1 berikut:
Tabel 1. Konsep dasar mekanika kuantum dan teori jaringan syaraf tiruan
Pasangan konsep dalam baris tabel yang sama tidak boleh diperlakukan sebagai analogi—bahkan, membangun analogi semacam itu adalah salah satu tujuan utama teori jaringan saraf kuantum. Sampai saat ini, konsep kuantum terutama digunakan untuk mengimplementasikan komputasi klasik. Konsep komputasi kuantum diperkenalkan pada tahun 1982 oleh Richard Feynman, yang mengeksplorasi peran efek kuantum dalam prosesor masa depan, yang elemen-elemennya mungkin berukuran atom. Pada tahun 1985, David Deutsch merumuskan konsep komputasi kuantum. Penting untuk dicatat bahwa efektivitas penggunaan jaringan saraf dikaitkan dengan pemrosesan informasi terdistribusi paralel yang masif dan nonlinier transformasi vektor masukan oleh neuron. Di sisi lain, sistem kuantum memiliki paralelisme kuantum yang jauh lebih kuat, yang dinyatakan dengan prinsip superposisi.
Saat mengembangkan konsep komputasi kuantum klasik dan saraf, interpretasi mekanika kuantum yang dipilih memainkan peran penting, di antaranya
Interpretasi Kopenhagen;
Formalisme integral jalur Feynman;
Interpretasi Banyak Dunia Everett, dll.
Pilihan interpretasi penting ketika membangun analogi antara mekanika kuantum dan neurocomputing. Secara khusus, penting untuk memecahkan masalah menghubungkan teori linier yaitu mekanika kuantum dengan pemrosesan data yang pada dasarnya nonlinier yang mendefinisikan kekuatan neuroteknologi.
2.2 Mengapa Jaringan Neural Kuantum menarik
Ada dua alasan utama ketertarikan pada jaringan saraf kuantum. Salah satunya melibatkan argumen bahwa proses kuantum mungkin memainkan peran penting dalam fungsi otak. Misalnya, Roger Penrose telah mengajukan berbagai argumen bahwa hanya fisika baru yang menyatukan mekanika kuantum dengan relativitas umum yang dapat menggambarkan fenomena seperti pemahaman dan kesadaran. Namun, pendekatannya tidak ditujukan pada jaringan saraf itu sendiri, melainkan pada struktur intraseluler seperti mikrotubulus. Alasan lainnya terkait dengan pesatnya pertumbuhan komputasi kuantum, yang ide utamanya dapat ditransfer ke neurocomputing, yang akan membuka kemungkinan baru bagi mereka.
Sistem saraf kuantum dapat mengatasi beberapa masalah sulit yang penting untuk komputasi kuantum karena sifat analognya dan kemampuannya untuk belajar dari sejumlah contoh yang terbatas.
Apa yang bisa kita harapkan dari jaringan saraf kuantum? Saat ini, jaringan saraf kuantum memiliki keunggulan sebagai berikut:
— kapasitas memori eksponensial;
— kinerja lebih baik dengan lebih sedikit neuron tersembunyi;
— belajar cepat;
-penghapusan bencana lupa karena tidak adanya gangguan gambar;
— memecahkan masalah yang tidak dapat dipisahkan secara linear dengan jaringan satu lapis;
— kurangnya koneksi;
— kecepatan pemrosesan data tinggi (10 10 bit/s);
- miniatur (10 11 neuron/mm 3);
— stabilitas dan keandalan yang lebih tinggi;
Manfaat potensial dari jaringan saraf kuantum inilah yang terutama memotivasi pengembangannya.
2. 3 Neuron kuantum
Sinapsis berkomunikasi antar neuron dan mengalikan sinyal masukan dengan angka yang mencirikan kekuatan koneksi—bobot sinapsis. Penambah melakukan penambahan sinyal yang datang melalui koneksi sinaptik dari neuron lain dan sinyal masukan eksternal. Konverter mengimplementasikan fungsi satu argumen, keluaran dari penambah, menjadi beberapa nilai keluaran neuron. Fungsi ini disebut fungsi aktivasi neuron.
Dengan demikian, neuron dijelaskan secara lengkap melalui bobot dan fungsi aktivasinya F. Setelah menerima sekumpulan angka (vektor) sebagai masukan, neuron menghasilkan sejumlah tertentu sebagai keluaran.
Fungsi aktivasi bisa bermacam-macam jenisnya. Opsi yang paling banyak digunakan ditunjukkan pada tabel (Tabel 2).
Tabel 2: Daftar fungsi aktivasi neuron
Definisi Neuron Kuantum diberikan sebagai berikut:
Ia menerima sinyal masukan (data awal atau sinyal keluaran dari neuron SSP lainnya) melalui beberapa saluran masukan. Setiap sinyal masukan melewati sambungan yang memiliki intensitas (atau bobot) tertentu; bobot ini sesuai dengan aktivitas sinaptik neuron. Setiap neuron memiliki nilai ambang tertentu yang terkait dengannya. Jumlah input tertimbang dihitung, nilai ambang batas dikurangi darinya, dan hasilnya adalah jumlah aktivasi neuron (juga disebut potensi pasca-sinaptik neuron - PSP).
Sinyal aktivasi diubah menggunakan fungsi aktivasi (atau fungsi transfer) untuk menghasilkan keluaran neuron (Gambar 1).
Gambar 1: Model matematika dari sebuah neuron
Model matematika dari neuron kuantum, di mana matriks bertindak berdasarkan operator yang dapat mengimplementasikan jaringan sel kuantum.
Misalnya: Proses pembelajaran neuron kuantum. = - operator identitas: .
Aturan pembelajaran kuantum diberikan dalam analogi dengan kasus klasik, sebagai berikut: di mana keluaran yang diinginkan. Aturan pembelajaran ini membawa neuron kuantum ke keadaan yang diinginkan untuk digunakan untuk pembelajaran. Dengan mengambil selisih antara kuadrat keluaran aktual dan yang diinginkan untuk modul, kita melihat bahwa:
Seluruh jaringan dapat dirakit dari elemen primitif menggunakan aturan standar arsitektur ANN.
2.4 Pembangunan Jaringan Syaraf Kuantum
Masalah ini diselesaikan dalam dua tahap: pemilihan jenis (arsitektur) CNN, pemilihan bobot (pelatihan) CNN.
Pada tahap pertama, kita harus memilih hal berikut: neuron mana yang ingin kita gunakan (jumlah input, fungsi transfer); bagaimana mereka harus terhubung satu sama lain? apa yang harus diambil sebagai input dan output dari SSP.
Sekilas tugas ini tampak besar, tetapi, untungnya, kita tidak harus membuat CNN “dari awal” - ada beberapa lusin arsitektur jaringan saraf yang berbeda, dan keefektifan banyak di antaranya telah terbukti secara matematis. Arsitektur yang paling populer dan dipelajari adalah perceptron multilayer, jaringan saraf regresi umum, jaringan saraf Kohonen dan lain-lain.
Pada tahap kedua, kita harus “melatih” jaringan yang dipilih, yaitu memilih nilai bobotnya sedemikian rupa sehingga berfungsi sesuai keinginan. SSP yang tidak terlatih seperti anak kecil—Anda bisa mengajarinya apa saja. Dalam jaringan saraf yang digunakan dalam praktik, jumlah bobot bisa mencapai puluhan ribu, sehingga pelatihan adalah proses yang sangat kompleks. Untuk banyak arsitektur, algoritme pembelajaran khusus telah dikembangkan yang memungkinkan Anda mengonfigurasi bobot CNN dengan cara tertentu. Algoritma yang paling populer adalah metode Error Back Propagation, yang digunakan, misalnya, untuk melatih perceptron.
2.5 Komputasi kuantum
Komputasi kuantum memungkinkan penyelesaian masalah yang tidak dapat diselesaikan pada komputer klasik. Misalnya, algoritme Shor memberikan solusi polinomial pada komputer kuantum untuk memfaktorkan bilangan bulat menjadi dua faktor prima, yang dianggap tidak dapat larut pada komputer klasik. Selain itu, algoritma Grover memberikan kecepatan yang signifikan ketika mencari data dalam database yang tidak berurutan.
Sejauh ini kita belum melihat perbedaan kualitatif antara penggunaan bit biasa dan qubit, namun sesuatu yang aneh terjadi ketika Anda memaparkan sebuah atom pada cahaya yang cukup untuk membuat elektron berada di tengah-tengah antara tingkat eksitasi. Karena elektron tidak dapat benar-benar berada di ruang antara level-level ini, maka elektron-elektron tersebut berada DI KEDUA level pada saat yang bersamaan. Ini dikenal sebagai "superposisi".
Superposisi ini memungkinkan penghitungan teoritis beberapa kemungkinan sekaligus, karena sekelompok qubit dapat mewakili beberapa angka sekaligus. Untuk menghitung menggunakan properti superposisi, Anda dapat membuat sekumpulan qubit, menempatkannya dalam status superposisi, lalu melakukan tindakan pada qubit tersebut.
Ketika algoritme selesai, superposisi dapat diciutkan, dan hasil tertentu akan diperoleh - yaitu, semua qubit akan menuju ke status 0 atau 1. Kita dapat menganggap bahwa algoritme bekerja secara paralel pada semua kemungkinan kombinasi status tertentu. qubit (yaitu 0 atau 1) adalah trik yang dikenal sebagai paralelisme kuantum (Tabel 3).
Tabel 3: Konsep utama komputasi kuantum
Membangun model sistem saraf kuantum (serta membuat model komputasi kuantum) menghadapi kebutuhan untuk memperjelas perhitungan mana yang dapat dicirikan sebagai benar-benar kuantum dan apa sumber efisiensi perhitungan ini.
Tempat penting juga ditempati dengan memperjelas bidang penerapan sistem komputasi kuantum yang paling efektif.
Sumber daya fundamental dan dasar pembentukan informasi kuantum adalah bit kuantum (qubit). Dari sudut pandang fisik, qubit mewakili keadaan ganda ideal dari sistem kuantum. Contoh sistem tersebut termasuk foton (polarisasi vertikal dan horizontal), elektron, dan sistem yang ditentukan oleh dua tingkat energi atom atau ion. Sejak awal, keadaan ganda suatu sistem telah memainkan peran penting dalam studi mekanika kuantum. Ini adalah sistem kuantum paling sederhana, dan pada prinsipnya semua sistem kuantum lainnya dapat dimodelkan dalam ruang keadaan kumpulan qubit.
Keadaan bit kuantum ditentukan oleh vektor dalam ruang vektor kompleks dua dimensi. Di sini vektor mempunyai dua komponen, dan proyeksinya ke basis ruang vektor adalah bilangan kompleks. Bit kuantum direpresentasikan (dalam notasi Dirac sebagai vektor ket) sebagai atau dalam notasi vektor (vektor bra). Jika, maka. Untuk keperluan komputasi kuantum, status dasar |0> dan |1> masing-masing mengkodekan nilai bit klasik 0 dan 1. Namun, tidak seperti bit klasik, qubit dapat berada dalam superposisi |0> dan |1>, seperti di mana dan merupakan bilangan kompleks yang memenuhi kondisi berikut:. Jika atau mengambil nilai nol, maka ini mendefinisikan keadaan klasik dan murni. Jika tidak, maka dikatakan berada dalam keadaan superposisi dua keadaan dasar klasik. Secara geometris, bit kuantum berada dalam keadaan kontinu antara dan sampai keadaannya diukur. Dalam kasus di mana sistem terdiri dari dua bit kuantum, ini digambarkan sebagai produk tensor. Misalnya, dalam notasi Dirac, sistem bit dua kuantum diberikan sebagai. Jumlah kemungkinan keadaan sistem gabungan meningkat secara eksponensial dengan penambahan bit kuantum.
Hal ini menyebabkan masalah dalam memperkirakan korelasi kuantum yang ada antara bit-bit kuantum dalam sistem komposit.
Pertumbuhan eksponensial dalam jumlah negara bagian ditambah dengan kemampuan untuk mengubah seluruh ruang (baik evolusi dinamis kesatuan suatu sistem, atau desain pengukuran subruang vektor eigen) memberikan landasan bagi komputasi kuantum. Karena transformasi kesatuan bersifat reversibel, komputasi kuantum (kecuali pengukuran) semuanya bersifat reversibel, sehingga membatasinya pada transformasi kuantum kesatuan. Ini berarti bahwa setiap sel kuantum (satu atau banyak qubit) melakukan komputasi yang dapat dibalik. Jadi, dengan adanya sel keluaran, penting untuk menentukan secara unik apa masukannya. Untungnya, ada teori klasik tentang komputasi reversibel, yang menyatakan bahwa setiap algoritma klasik dapat dibuat reversibel dengan batas atas yang dapat diterima, sehingga batasan pada komputasi kuantum ini tidak menimbulkan masalah serius. Namun, ini adalah sesuatu yang harus dipertimbangkan ketika mengusulkan spesifikasi gerbang kuantum.
2.6 model KNS
Ada beberapa lembaga penelitian di seluruh dunia yang sedang mengerjakan konsep jaringan saraf kuantum, seperti Georgia Tech University dan Universitas Oxford. Namun, sebagian besar menahan diri untuk tidak mempublikasikan karya mereka. Hal ini mungkin disebabkan oleh fakta bahwa penerapan jaringan saraf kuantum berpotensi jauh lebih sederhana dibandingkan komputer kuantum konvensional, dan setiap institusi ingin memenangkan perlombaan kuantum. Secara teori, membangun jaringan saraf kuantum lebih mudah daripada komputer kuantum karena satu alasan. Alasan ini adalah koherensi. Superposisi banyak qubit mengurangi resistensi terhadap derau di komputer kuantum, dan derau berpotensi menyebabkan runtuhnya atau dekoherensi superposisi sebelum komputasi yang berguna dapat dilakukan. Namun, karena jaringan saraf kuantum tidak memerlukan periode yang sangat lama atau superposisi yang sangat banyak per neuron, jaringan tersebut tidak terlalu rentan terhadap noise, dan tetap melakukan perhitungan serupa dengan yang dilakukan oleh jaringan saraf konvensional, namun jauh lebih cepat (sebenarnya secara eksponensial) .
Jaringan saraf kuantum dapat mewujudkan keunggulan kecepatan eksponensialnya dengan menggunakan superposisi besaran masukan dan keluaran neuron. Namun manfaat lain yang dapat diperoleh adalah karena neuron dapat memproses superposisi sinyal, jaringan saraf sebenarnya dapat memiliki lebih sedikit neuron di lapisan tersembunyi ketika belajar memperkirakan fungsi tertentu. Hal ini akan memungkinkan untuk membangun jaringan yang lebih sederhana dengan lebih sedikit neuron dan, oleh karena itu, meningkatkan stabilitas dan keandalan operasinya (yaitu, jumlah peluang jaringan kehilangan koherensi akan berkurang). Dengan mempertimbangkan semua ini, tidak bisakah jaringan saraf kuantum secara komputasi lebih kuat daripada jaringan biasa? Saat ini, jawabannya sepertinya tidak, karena semua model kuantum menggunakan jumlah qubit yang terbatas untuk melakukan penghitungannya, dan ini merupakan batasannya.
2.7 Keadaan kuantum dan representasinya
robotika perceptron neuron kuantum
Keadaan kuantum dan operator komputasi kuantum keduanya penting untuk memahami paralelisme dan plastisitas dalam sistem pemrosesan informasi.
Dalam rangkaian logika kuantum, keadaan kuantum fundamental adalah rotasi satu bit dari keadaan Ui, ditunjukkan pada Gambar. 2, dan status NOT yang digerakkan dua-bit ditunjukkan pada Gambar. 3. Keadaan pertama memutar keadaan kuantum masukan ke keadaan ini sepanjang dan. Negara bagian terakhir melakukan operasi XOR.
Beras. 2. Status rotasi satu bit
Beras. 3. Dua-bit BUKAN kontrol negara
Kami memilih evaluasi kompleks berikut dari representasi Persamaan. (3) secara terbatas sesuai dengan keadaan kubik dalam Persamaan. (1).
(3)
Persamaan (3) memungkinkan untuk menyatakan operasi berikut: keadaan rotasi dan keadaan NOT yang dikontrol dua bit.
a) Operasi keadaan rotasi
Keadaan rotasi adalah fase keadaan bergerak yang mengubah fase menjadi keadaan kubik. Karena keadaan kubik diwakili oleh Persamaan. (3), negara dipahami sebagai hubungan berikut:
(4)
b) Operasi NOT yang dikontrol dua bit
Operasi ini ditentukan oleh parameter masukan r sebagai berikut:
(5)
dimana r=1 berhubungan dengan rotasi pembatalan, dan r=0 berhubungan dengan non-rotasi. Dalam kasus r=0, fase probabilitas amplitudo keadaan kuantum |1> berubah total.
Namun, probabilitas yang diamati adalah invarian sehingga kami menganggap kasus ini sebagai nonrotasi.
3. Pelatihan SSP
Jaringan saraf kuantum efektif dalam menjalankan fungsi kompleks di sejumlah area. Ini termasuk pengenalan pola, klasifikasi, visi, sistem kontrol, dan prediksi.
Kemampuan untuk belajar—untuk beradaptasi dengan kondisi dan peluang dalam lingkungan eksternal yang berubah—merupakan fitur penting dari jaringan saraf yang kini disertakan sebagai poin terpisah pada apa yang disebut “uji Turing”, yang merupakan definisi operasional dari konsep kecerdasan.
Sebuah tes empiris yang idenya dikemukakan oleh Alan Turing dalam artikel “Computing Machinery and Intelligence” yang diterbitkan pada tahun 1950 di jurnal filosofis Mind. Tujuan dari tes ini adalah untuk mengetahui kemungkinan pemikiran buatan yang dekat dengan manusia.
Interpretasi standar dari tes ini adalah: “Seseorang berinteraksi dengan satu komputer dan satu orang. Berdasarkan jawaban atas pertanyaan yang diajukan, ia harus menentukan dengan siapa ia berbicara: seseorang atau program komputer. Tujuan dari program komputer adalah untuk menyesatkan seseorang agar membuat pilihan yang salah.” Semua peserta tes tidak dapat saling melihat.
Secara umum, belajar adalah perubahan perilaku yang relatif permanen yang disebabkan oleh pengalaman. Pembelajaran di SSP merupakan proses yang lebih langsung, dan dapat menangkap pembelajaran setiap langkah dalam hubungan sebab akibat yang berbeda. Pengetahuan tentang jaringan saraf yang disimpan dalam sinapsis merupakan bobot hubungan antar neuron. Bobot antara dua lapisan neuron ini dapat direpresentasikan sebagai matriks. Jika jaringan saraf dengan algoritma pembelajaran yang tepat ditentukan untuk menganalisis dan memproses data terlebih dahulu, maka prediksi yang masuk akal dapat dibuat.
Pengertian proses pembelajaran mengandung arti rangkaian peristiwa sebagai berikut:
· Jaringan saraf dirangsang oleh lingkungan.
· Jaringan saraf mengalami perubahan parameter bebasnya sebagai akibat dari eksitasi.
· Jaringan merespons lingkungan dengan cara baru karena perubahan yang terjadi pada struktur internalnya.
Ada banyak algoritma yang tersedia dan diharapkan ada beberapa algoritma unik untuk merancang model QNN. Perbedaan kedua algoritma tersebut terletak pada formulasi yang dapat mengubah bobot neuron, dan hubungan neuron dengan lingkungannya.
Semua metode pengajaran dapat diklasifikasikan menjadi dua kategori utama: diawasi dan tidak diawasi.
Tabel 4 menyajikan berbagai algoritma pembelajaran dan arsitektur jaringan terkait (daftar ini tidak lengkap). Kolom terakhir mencantumkan tugas-tugas di mana setiap algoritma dapat diterapkan. Setiap algoritma pembelajaran difokuskan pada jaringan dengan arsitektur tertentu dan ditujukan untuk kelas tugas terbatas. Selain yang dibahas, beberapa algoritma lain harus disebutkan: Adaline dan Madaline, analisis diskriminan linier, proyeksi Sammon, analisis komponen utama.
Tabel 4: Algoritma pembelajaran yang diketahui:
Paradigma | Aturan Pembelajaran | Arsitektur | Algoritma pembelajaran | ||
Dengan guru | Koreksi Kesalahan | Perceptron satu lapis dan multi lapis | Algoritma pelatihan PerceptronPropagasi mundurAdaline dan Madaline | pelatihan perseptronPropagasi mundurAdaline dan MadalineKlasifikasi gambarPerkiraan fungsiPrediksi, kontrol | |
Boltzmann | Berulang | Algoritma pembelajaran Boltzmann | Klasifikasi gambar | ||
Analisis diskriminan linier | Analisis DataKlasifikasi gambar | ||||
Kompetisi | Kompetisi | Kuantisasi vektor | |||
Klasifikasi gambar | |||||
Tanpa seorang guru | Koreksi Kesalahan | Propagasi langsung multilayer | proyeksi Sammon | ||
Distribusi atau kompetisi langsung | Analisis Komponen Utama | Analisis DataKompresi data | |||
jaringan Hopfield | Pelatihan memori asosiatif | Memori asosiatif | |||
Kompetisi | Kompetisi | Kuantisasi vektor | KategorisasiKompresi data | ||
SOM Kohonen | SOM Kohonen | KategorisasiAnalisis Data | |||
Campur aduk | Koreksi kesalahan dan persaingan | Algoritma pembelajaran RBF | Klasifikasi gambarPerkiraan fungsiPrediksi, kontrol | ||
Melatih suatu jaringan berarti menyampaikan apa yang kita inginkan darinya. Proses ini sangat mirip dengan mengajar anak alfabet. Setelah menunjukkan kepada anak gambar huruf “A”, kami bertanya kepadanya: “Huruf apa ini?” Jika jawabannya salah, kami memberi tahu anak itu jawaban yang kami ingin dia berikan: “Ini huruf A.” Anak mengingat contoh tersebut beserta jawaban yang benar, yaitu terjadi beberapa perubahan dalam ingatannya ke arah yang benar. Proses penyajian huruf-huruf tersebut akan kami ulangi berulang-ulang hingga ke-33 huruf tersebut benar-benar hafal. Proses ini disebut “pembelajaran yang diawasi” (Gbr. 4).
Beras. 4. Proses “belajar dengan seorang guru”.
Saat melatih jaringan, kami bertindak dengan cara yang persis sama. Kami memiliki beberapa database yang berisi contoh (satu set gambar huruf tulisan tangan). Dengan menampilkan gambar huruf “A” pada input CNS, kita mendapatkan beberapa jawaban, belum tentu benar. Kami juga mengetahui jawaban yang benar (diinginkan) - dalam hal ini, kami ingin level sinyal pada output SNS berlabel “A” menjadi maksimal. Biasanya, keluaran yang diinginkan dalam masalah klasifikasi adalah himpunan (1, 0, 0, ...), di mana 1 pada keluaran berlabel “A”, dan 0 pada semua keluaran lainnya. Dengan menghitung selisih antara respon yang diinginkan dan respon jaringan yang sebenarnya, kita mendapatkan 33 angka - vektor kesalahan. Algoritme propagasi balik kesalahan adalah sekumpulan rumus yang memungkinkan Anda menghitung koreksi yang diperlukan untuk bobot jaringan saraf menggunakan vektor kesalahan. Kita dapat menampilkan huruf yang sama (serta gambar berbeda dari huruf yang sama) ke jaringan saraf berkali-kali. Dalam pengertian ini, belajar lebih seperti mengulangi latihan dalam olahraga—pelatihan.
Setelah presentasi contoh berulang kali, bobot KNN menjadi stabil, dan KNN memberikan jawaban yang benar untuk semua (atau hampir semua) contoh dari database. Dalam hal ini, mereka mengatakan bahwa “jaringan telah mempelajari semua contoh”, “jaringan saraf telah dilatih”, atau “jaringan telah dilatih”. Dalam implementasi perangkat lunak, Anda dapat melihat bahwa selama proses pembelajaran, besarnya kesalahan (jumlah kesalahan kuadrat pada semua keluaran) secara bertahap menurun. Ketika kesalahan mencapai nol atau tingkat kecil yang dapat diterima, pelatihan dihentikan, dan jaringan yang dihasilkan dianggap terlatih dan siap digunakan pada data baru.
Pelatihan jaringan dibagi menjadi beberapa tahapan sebagai berikut:
Inisialisasi jaringan: Bobot dan bias jaringan diberi nilai acak kecil dari rentang dan masing-masing.
Definisi elemen sampel pelatihan: (<текущий вход>, <желаемый выход>). Input saat ini (x0, x1... xN-1) harus berbeda untuk semua elemen set pelatihan. Saat menggunakan perceptron multilayer sebagai pengklasifikasi, sinyal keluaran yang diinginkan (d0, d1...dN-1) terdiri dari nol kecuali untuk satu elemen satuan yang sesuai dengan kelas di mana sinyal masukan saat ini berada.
Perhitungan sinyal keluaran saat ini: Sinyal keluaran saat ini ditentukan sesuai dengan skema operasi tradisional jaringan saraf multilayer.
Penyetelan bobot sinaptik: Penyetelan bobot menggunakan algoritma rekursif yang pertama kali diterapkan pada neuron keluaran jaringan dan kemudian melintasi jaringan mundur ke lapisan pertama. Bobot sinaptik disesuaikan dengan rumus:
,
dimana w ij adalah bobot dari neuron i atau dari elemen sinyal input i ke neuron j pada waktu t, x i" adalah output dari neuron i atau elemen ke-i dari sinyal input, r adalah langkah pembelajaran, g j adalah nilai kesalahan untuk neuron j. Jika nomor neuron j termasuk dalam lapisan terakhir, maka
,
dimana dj adalah keluaran yang diinginkan dari neuron j, yj adalah keluaran saat ini dari neuron j. Jika neuron nomor j termasuk dalam salah satu lapisan dari lapisan pertama hingga kedua dari belakang, maka
,
dimana k melewati semua neuron pada lapisan dengan nomor satu lebih besar dari nomor yang dimiliki neuron j. Bias eksternal neuron b disesuaikan dengan cara yang sama.
Model yang dipertimbangkan dapat digunakan untuk pengenalan pola, klasifikasi, dan prediksi. Telah dilakukan upaya untuk membangun sistem pakar berbasis perceptron multilayer dengan pelatihan menggunakan metode backpropagation. Penting untuk dicatat bahwa semua informasi yang dimiliki CNN tentang masalah ini terdapat dalam kumpulan contoh. Oleh karena itu, kualitas pelatihan CNN secara langsung bergantung pada jumlah contoh dalam set pelatihan, serta seberapa lengkap contoh-contoh tersebut menggambarkan tugas yang diberikan. Sekali lagi, melatih jaringan saraf adalah proses yang kompleks dan membutuhkan banyak pengetahuan. Algoritma pembelajaran KNN memiliki berbagai parameter dan pengaturan, yang pengelolaannya memerlukan pemahaman tentang pengaruhnya.
3.1 Penerapan Jaringan Syaraf Kuantum. Arti dari algoritma pembelajaran yang diawasi
Kelas masalah yang dapat diselesaikan dengan menggunakan CNN ditentukan oleh cara kerja jaringan dan cara pembelajarannya. Selama operasi, SSP menerima nilai variabel masukan dan menghasilkan nilai variabel keluaran. Dengan demikian, jaringan dapat digunakan dalam situasi di mana Anda memiliki beberapa informasi yang diketahui dan ingin memperoleh informasi yang belum diketahui darinya (Patterson, 1996; Fausett, 1994). Berikut beberapa contoh tugas tersebut:
· Pengenalan dan klasifikasi pola
Objek yang sifatnya berbeda dapat bertindak sebagai gambar: simbol teks, gambar, sampel suara, dll. Saat melatih jaringan, berbagai sampel gambar ditawarkan, yang menunjukkan kelas mana mereka berasal. Sampel biasanya direpresentasikan sebagai vektor nilai fitur. Dalam hal ini, totalitas semua karakteristik harus secara jelas menentukan kelas sampel tersebut. Jika fiturnya tidak cukup, jaringan mungkin menetapkan sampel yang sama ke beberapa kelas, dan hal ini tidak benar. Setelah jaringan dilatih, jaringan tersebut dapat disajikan dengan gambar yang sebelumnya tidak diketahui dan menerima respons tentang milik kelas tertentu.
·Pengambilan keputusan dan manajemen
Tugas ini dekat dengan masalah klasifikasi. Situasi yang karakteristiknya diperoleh dari input SSP harus diklasifikasikan. Pada keluaran jaringan, tanda keputusan yang diambil akan muncul. Dalam hal ini, berbagai kriteria untuk menggambarkan keadaan sistem yang dikendalikan digunakan sebagai sinyal masukan.
· Pengelompokan
Clustering mengacu pada pembagian sekumpulan sinyal input ke dalam kelas-kelas, meskipun faktanya baik jumlah maupun karakteristik kelas-kelas tersebut tidak diketahui sebelumnya. Setelah pelatihan, jaringan tersebut dapat menentukan kelas mana yang termasuk dalam sinyal input.
· Peramalan
Setelah pelatihan, jaringan mampu memprediksi nilai masa depan dari suatu rangkaian tertentu berdasarkan beberapa nilai sebelumnya dan/atau beberapa faktor yang ada saat ini. Perlu dicatat bahwa peramalan hanya mungkin terjadi jika perubahan sebelumnya, sampai batas tertentu, benar-benar menentukan perubahan di masa depan.
· Perkiraan
Teorema pendekatan umum telah dibuktikan: dengan menggunakan operasi linier dan koneksi kaskade, dimungkinkan untuk memperoleh perangkat dari elemen nonlinier sembarang yang menghitung fungsi kontinu dengan akurasi yang telah ditentukan.
· Kompresi Data dan Memori Asosiatif
Kemampuan jaringan saraf untuk mengidentifikasi hubungan antara berbagai parameter memungkinkan untuk mengekspresikan data berdimensi tinggi secara lebih kompak jika data tersebut saling terkait erat satu sama lain. Proses sebaliknya - memulihkan kumpulan data asli dari sepotong informasi - disebut memori asosiatif otomatis. Memori asosiatif juga memungkinkan Anda memulihkan sinyal/gambar asli dari data input yang berisik/rusak. Memecahkan masalah memori heteroasosiatif memungkinkan kita mengimplementasikan memori yang dapat dialamatkan konten.
Tahapan pemecahan masalah:
— pengumpulan data untuk pelatihan;
— persiapan dan normalisasi data;
— pilihan topologi jaringan;
— pemilihan eksperimental karakteristik jaringan;
pelatihan sebenarnya;
— memeriksa kecukupan pelatihan;
— penyesuaian parameter, pelatihan akhir;
— verbalisasi jaringan untuk digunakan lebih lanjut.
Jadi, mari kita beralih ke syarat penting kedua untuk penggunaan Jaringan Syaraf Kuantum: kita harus mengetahui bahwa ada hubungan antara nilai masukan yang diketahui dan keluaran yang tidak diketahui. Komunikasi ini dapat terdistorsi oleh kebisingan.
Sebagai aturan, QNN digunakan ketika jenis koneksi yang tepat antara input dan output tidak diketahui - jika diketahui, maka koneksi dapat dimodelkan secara langsung. Fitur penting lainnya dari QNN adalah hubungan antara input dan output ditemukan selama proses pelatihan jaringan. Untuk melatih CNN, dua jenis algoritma digunakan (jenis jaringan yang berbeda menggunakan jenis pelatihan yang berbeda): diawasi (“pembelajaran yang diawasi”) dan tanpa pengawasan (“tanpa pengawasan”). Metode yang paling umum digunakan adalah pembelajaran yang diawasi.
Untuk pelatihan jaringan yang diawasi, pengguna harus menyiapkan kumpulan data pelatihan. Data ini adalah contoh masukan dan keluarannya. Jaringan belajar membuat koneksi antara yang pertama dan kedua. Biasanya, data pelatihan diambil dari data historis. Ini juga dapat mencakup nilai harga saham dan indeks FTSE, informasi tentang peminjam sebelumnya – data pribadi mereka dan apakah mereka berhasil memenuhi kewajibannya, contoh posisi robot dan reaksi yang benar.
CNN kemudian dilatih menggunakan beberapa bentuk algoritma pembelajaran terawasi (yang paling terkenal adalah metode propagasi mundur yang diusulkan oleh Rumelhart et al., 1986), di mana data yang tersedia digunakan untuk menyesuaikan bobot dan ambang batas jaringan sedemikian rupa. untuk meminimalkan kesalahan perkiraan pada set pelatihan. Jika jaringan dilatih dengan baik, jaringan tersebut memperoleh kemampuan untuk memodelkan fungsi (yang tidak diketahui) yang menghubungkan nilai variabel masukan dan keluaran, dan jaringan tersebut selanjutnya dapat digunakan untuk membuat prediksi dalam situasi di mana nilai keluarannya adalah tidak dikenal.
3.2 Perceptron satu lapis dan multi lapis
3.2.1 Perceptron lapisan tunggal. Pendidikan
Secara historis, jaringan saraf tiruan pertama yang mampu melakukan persepsi (persepsi) dan pembentukan reaksi terhadap stimulus yang dirasakan adalah Perseptron Rosenblatt (F.Rosenblatt, 1957). Istilah " Perseptron" berasal dari bahasa Latin persepsi, yang berarti persepsi, kognisi. Analoginya dalam bahasa Rusia untuk istilah ini adalah "Perceptron". Penulisnya menganggap perceptron bukan sebagai perangkat komputasi teknis tertentu, tetapi sebagai model fungsi otak. Pekerjaan modern pada jaringan saraf tiruan jarang mencapai tujuan seperti itu.
Perceptron klasik paling sederhana berisi tiga jenis elemen (Gbr. 5.).
Beras. 5. Perceptron Rosenblatt Dasar
Perceptron satu lapis dicirikan oleh matriks koneksi sinaptik ||W|| dari elemen S- ke A. Elemen matriks berhubungan dengan hubungan yang mengarah dari elemen S ke-i (baris) ke elemen A ke-j (kolom). Matriks ini sangat mirip dengan matriks frekuensi absolut dan isi informasi yang dibentuk dalam model informasi semantik berdasarkan teori sistem informasi.
Dari sudut pandang neuroinformatika modern, perceptron lapisan tunggal terutama memiliki kepentingan historis; namun, konsep dasar dan algoritma sederhana untuk melatih jaringan saraf dapat dipelajari dengan menggunakan contohnya.
Pelatihan jaringan saraf klasik terdiri dari penyesuaian koefisien bobot setiap neuron.
F. Rosenblatt mengusulkan algoritma pembelajaran berulang yang terdiri dari 4 langkah, yang terdiri dari penyesuaian matriks bobot yang secara konsisten mengurangi kesalahan pada vektor keluaran:
Langkah 1: Nilai awal bobot semua neuron diasumsikan acak.
Langkah 2: Gambar masukan x a disajikan ke jaringan, menghasilkan gambar keluaran.
Langkah 3: Vektor kesalahan yang dibuat oleh jaringan pada keluaran dihitung. Vektor-vektor koefisien pembobotan disesuaikan sedemikian rupa sehingga besarnya penyesuaian sebanding dengan kesalahan keluaran dan sama dengan nol jika kesalahannya nol:
b hanya komponen matriks bobot yang sesuai dengan nilai masukan bukan nol yang diubah;
b tanda kenaikan bobot sesuai dengan tanda kesalahan, yaitu kesalahan positif (nilai keluaran kurang dari yang disyaratkan) menyebabkan peningkatan koneksi;
b Pembelajaran setiap neuron terjadi secara independen dari pembelajaran neuron lainnya, yang sesuai dengan prinsip pembelajaran lokal, yang penting dari sudut pandang biologis.
Langkah 4: Langkah 1−3 diulangi untuk semua vektor pelatihan. Satu siklus penyajian berurutan dari seluruh sampel disebut suatu zaman. Pelatihan berakhir setelah beberapa epoch jika setidaknya salah satu dari kondisi berikut terpenuhi:
b ketika iterasi bertemu, yaitu vektor bobot berhenti berubah;
b ketika kesalahan absolut total yang dijumlahkan terhadap semua vektor menjadi kurang dari nilai kecil tertentu.
3.2.2 Perceptron berlapis-lapis. Pelatihan Perceptron Multilapis
Ini mungkin arsitektur jaringan yang paling umum digunakan saat ini. Ini diusulkan oleh Rumelhart dan McClelland (1986) dan dibahas secara rinci di hampir semua buku teks tentang jaringan saraf (lihat, misalnya, Bishop, 1995). Setiap elemen jaringan menyusun jumlah masukan tertimbang, disesuaikan sebagai suatu suku, dan kemudian meneruskan nilai aktivasi ini melalui fungsi transfer untuk menghasilkan nilai keluaran elemen tersebut. Elemen-elemen tersebut disusun dalam topologi lapis demi lapis dengan transmisi sinyal langsung. Jaringan seperti itu dapat dengan mudah diartikan sebagai model input-output, di mana bobot dan ambang batas (bias) merupakan parameter bebas model. Jaringan seperti itu dapat memodelkan suatu fungsi dengan tingkat kompleksitas apa pun, dengan jumlah lapisan dan jumlah elemen di setiap lapisan menentukan kompleksitas fungsi tersebut. Menentukan jumlah lapisan perantara dan jumlah elemen di dalamnya merupakan isu penting ketika merancang perceptron multilayer (Haykin, 1994; Bishop, 1995).
Banyaknya elemen input dan output ditentukan oleh kondisi permasalahan. Keraguan mungkin timbul mengenai nilai input mana yang akan digunakan dan mana yang tidak. Kita asumsikan bahwa variabel masukan dipilih secara intuitif dan semuanya signifikan. Pertanyaan tentang berapa banyak lapisan perantara dan elemen yang akan digunakan di dalamnya masih belum jelas. Sebagai perkiraan awal, kita dapat mengambil satu lapisan perantara, dan menetapkan jumlah elemen di dalamnya sama dengan setengah jumlah elemen masukan dan keluaran. Sekali lagi, kami akan membahas masalah ini lebih terinci nanti.
Perceptron multilayer adalah sistem pengenalan yang dapat dilatih yang mengimplementasikan aturan keputusan linier, disesuaikan selama proses pembelajaran, dalam ruang fitur sekunder, yang biasanya merupakan fungsi ambang batas linier yang dipilih secara acak dari fitur utama.
Selama pelatihan, sinyal dari sampel pelatihan disuplai secara bergantian ke input perceptron, serta instruksi tentang kelas di mana sinyal ini harus ditetapkan. Pelatihan perceptron terdiri dari koreksi bobot untuk setiap kesalahan pengenalan, yaitu untuk setiap kasus ketidaksesuaian antara solusi yang dihasilkan oleh perceptron dan kelas sebenarnya. Jika perceptron salah memberikan sinyal ke kelas tertentu, maka bobot fungsi, kelas sebenarnya, bertambah, dan bobot kelas yang salah berkurang. Jika penyelesaiannya benar, semua bobot tetap tidak berubah (Gbr. 6.).
Beras. 6. Perceptron lapisan ganda
Contoh: Misalkan sebuah perceptron, yaitu sistem dengan n saluran masukan dan saluran keluaran y. Keluaran dari perceptron klasik adalah fungsi aktivasi perceptron dan merupakan penyetelan bobot selama proses pelatihan. Algoritma pelatihan perceptron bekerja sebagai berikut.
1. Bobot diinisialisasi dalam jumlah kecil.
2. Vektor sampel mewakili perceptron dan keluaran y yang diperoleh sesuai aturan
3. Bobot diperbarui menurut aturan di mana t adalah waktu diskrit dan d adalah keluaran yang diinginkan untuk pelatihan dan merupakan langkahnya.
Komentar. Kecil kemungkinannya untuk membuat analogi yang tepat dari fungsi aktivasi nonlinier F, seperti sigmoid dan fungsi umum lainnya dalam jaringan saraf, mungkin untuk kasus kuantum.
3.3 Algoritma Propagasi Balik
Pada pertengahan 1980-an, beberapa peneliti secara independen mengusulkan algoritma yang efisien untuk melatih perceptron multilayer berdasarkan penghitungan gradien fungsi kesalahan. Algoritma ini disebut "propagasi mundur".
Algoritma propagasi balik adalah algoritma pembelajaran gradien berulang yang digunakan untuk meminimalkan deviasi standar keluaran saat ini dan keluaran yang diinginkan dari jaringan saraf multilayer.
Dalam neuroparadigma “propagasi balik”, fungsi transfer sigmoidal paling sering digunakan, misalnya
Fungsi sigmoidal meningkat secara monoton dan memiliki turunan bukan nol di seluruh domain definisi. Karakteristik ini memastikan berfungsinya dan pembelajaran jaringan dengan baik.
Berfungsinya jaringan multilayer dilakukan sesuai dengan rumus:
dimana s adalah keluaran penambah, w adalah bobot koneksi, y adalah keluaran neuron, b adalah bias, i adalah jumlah neuron, N adalah jumlah neuron dalam lapisan, m adalah jumlah lapisan, L adalah jumlah lapisan, f adalah fungsi aktivasi.
Metode propagasi balik-- cara menghitung gradien fungsi kesalahan dengan cepat.
Perhitungan dilakukan dari lapisan keluaran ke lapisan masukan menggunakan rumus berulang dan tidak memerlukan penghitungan ulang nilai keluaran neuron.
Kesalahan propagasi mundur memungkinkan pengurangan biaya komputasi penghitungan gradien berkali-kali lipat dibandingkan dengan penghitungan dengan menentukan gradien. Mengetahui gradien, Anda dapat menerapkan banyak metode teori optimasi yang menggunakan turunan pertama.
Dalam algoritma backpropagation, vektor gradien dari permukaan kesalahan dihitung. Vektor ini menunjukkan arah penurunan terpendek sepanjang permukaan dari suatu titik tertentu, sehingga jika kita bergerak “sedikit” maka kesalahannya akan berkurang. Serangkaian langkah-langkah tersebut (melambat saat Anda mendekati dasar) pada akhirnya akan menghasilkan minimal satu jenis atau lainnya. Kesulitan tertentu di sini adalah pertanyaan tentang berapa lama langkah yang harus diambil.
Tentu saja, dengan pelatihan jaringan saraf seperti itu, tidak ada kepastian bahwa jaringan tersebut telah belajar dengan cara terbaik, karena selalu ada kemungkinan algoritme jatuh ke minimum lokal (Gbr. 7.). Untuk tujuan ini, teknik khusus digunakan untuk “mengeluarkan” solusi yang ditemukan dari ekstrem lokal. Jika setelah beberapa tindakan seperti itu, jaringan saraf menyatu ke solusi yang sama, maka kita dapat menyimpulkan bahwa solusi yang ditemukan kemungkinan besar adalah solusi optimal.
Beras. 7. Metode penurunan gradien untuk meminimalkan kesalahan jaringan
3.4 Algoritma genetika. Masalah klasik penjual keliling
Algoritma genetika (GA) mampu menyetel CNN secara optimal dengan dimensi ruang pencarian yang cukup untuk memecahkan sebagian besar masalah praktis. Selain itu, jangkauan aplikasi yang dipertimbangkan jauh melebihi kemampuan algoritma backpropagation.
Pemrosesan informasi dengan algoritma genetika menggunakan dua mekanisme utama untuk memilih sifat-sifat yang berguna, yang dipinjam dari gagasan modern tentang seleksi alam: mutasi dalam rantai terpisah dan persilangan antara dua rantai. Mari kita pertimbangkan mekanisme ini secara lebih rinci (Tabel 5).
Tabel 5: Mutasi dan persilangan
Gambar tersebut menunjukkan tahapan pertukaran informasi yang berurutan antara dua rantai selama penyeberangan. Rantai baru yang dihasilkan (atau salah satunya) selanjutnya dapat dimasukkan ke dalam populasi jika rangkaian fitur yang ditentukan memberikan nilai terbaik dari fungsi tujuan. Jika tidak, mereka akan tersingkir, dan nenek moyang mereka akan tetap berada dalam populasi. Mutasi dalam rantai genetik bersifat titik: pada suatu titik acak dalam rantai, salah satu kode digantikan oleh kode lain (nol dengan satu, dan satu dengan nol) | "www..
Dari sudut pandang sistem pemrosesan informasi buatan, pencarian genetik adalah metode khusus untuk menemukan solusi terhadap masalah optimasi. Selain itu, pencarian berulang tersebut menyesuaikan dengan karakteristik fungsi tujuan: rantai yang lahir dalam proses uji persilangan semakin memperluas area ruang fitur dan sebagian besar berlokasi di wilayah optimal. Mutasi yang relatif jarang mencegah degenerasi kumpulan gen, yang setara dengan pencarian optimal yang jarang namun tidak pernah berakhir di semua area lain dalam ruang karakteristik.
Dalam sepuluh tahun terakhir, banyak metode pelatihan CNN yang diawasi menggunakan GA telah dikembangkan. Hasil yang diperoleh membuktikan besarnya kemungkinan simbiosis tersebut. Kombinasi penggunaan algoritma QNN dan GA juga memiliki keunggulan ideologis karena termasuk dalam metode pemodelan evolusioner dan dikembangkan dalam kerangka paradigma teknologi yang sama yang meminjam metode dan mekanisme alami sebagai yang paling optimal.
Untuk mensimulasikan proses evolusi, pertama-tama kita menghasilkan populasi acak - beberapa individu dengan kumpulan kromosom acak (vektor numerik). Algoritma genetika mensimulasikan evolusi populasi ini sebagai proses siklus persilangan individu dan perubahan generasi (Gbr. 8.).
Beras. 8. Algoritma perhitungan Mari kita pertimbangkan kelebihan dan kekurangan metode standar dan genetik dengan menggunakan contoh masalah travelling salesman klasik (TSP - travelling salesman problem). Inti permasalahannya adalah menemukan jalur tertutup terpendek di sekitar beberapa kota berdasarkan koordinatnya. Ternyata di 30 kota yang ada, menemukan jalur optimal merupakan tugas yang kompleks, yang mendorong pengembangan berbagai metode baru (termasuk jaringan saraf dan algoritma genetika).
Isi formulir dengan pekerjaan Anda saat iniKementerian Pendidikan dan Ilmu Pengetahuan Federasi Rusia Institusi pendidikan negara wilayah Moskow Universitas Internasional Alam, Masyarakat dan Manusia "Dubna" Tesis master Topik Jaringan saraf kuantum dalam proses pembelajaran dan manajemen Siswa Olga Aleksandrovna Afanasyeva Abstrak Karya ini didedikasikan untuk analisis jaringan saraf kuantum...
Tesis master, bahasa Rusia
tesis master